What is Bruin?+
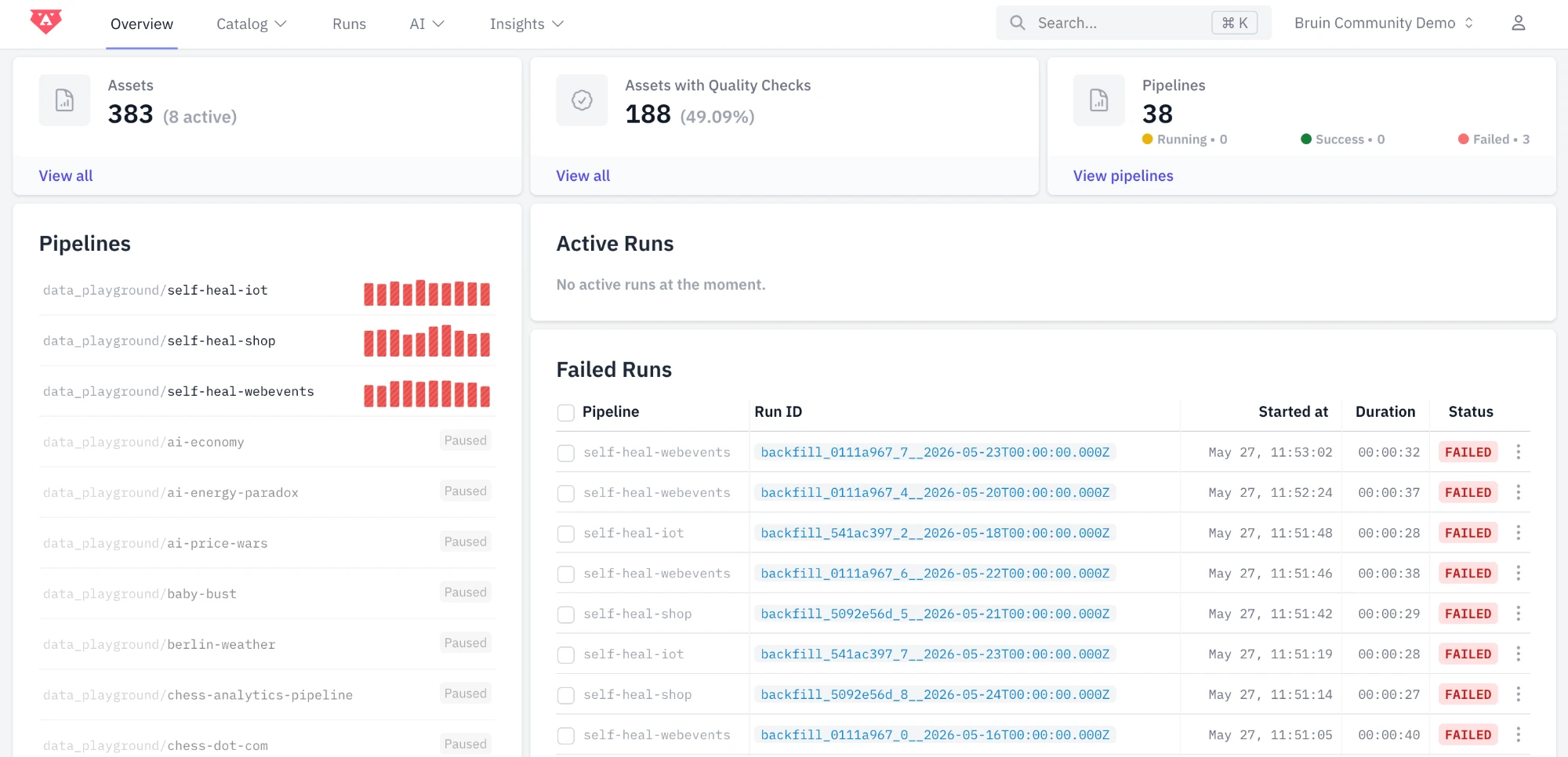
Bruin is an end-to-end AI data platform that combines data ingestion (databases, warehouses, SaaS apps, files, APIs, and event streams), SQL and Python pipelines, automated quality checks, column-level lineage, and an AI data analyst that lives in Slack, Microsoft Teams, Google Chat, WhatsApp, Discord, Telegram, email, and Bruin Cloud. It replaces the typical Fivetran + dbt + Airflow + BI + ChatGPT-on-data stack with one platform.
Where can I use Bruin?+
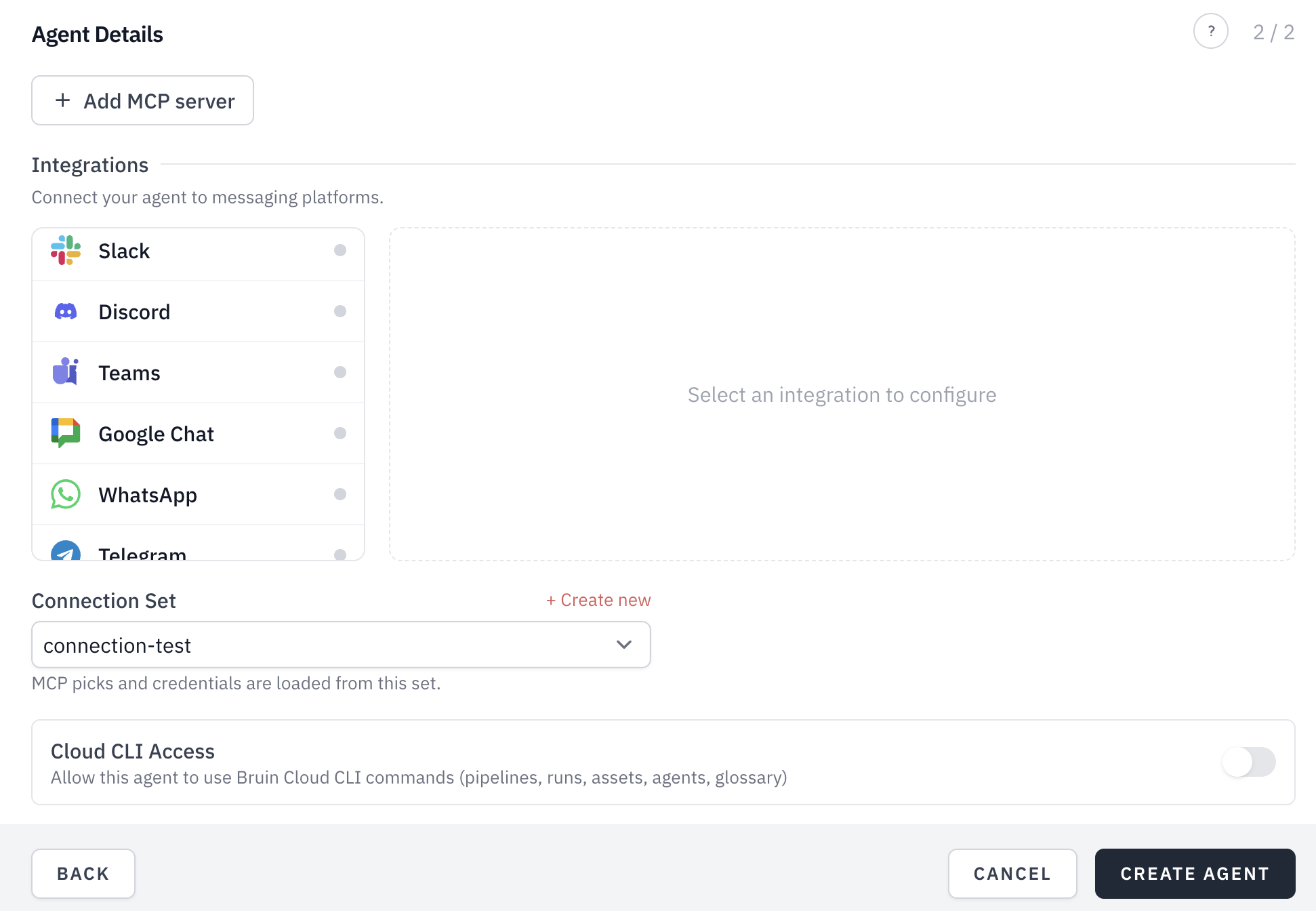
Anywhere your team already works. Bruin lives in Slack, Microsoft Teams, Google Chat, WhatsApp, Discord, Telegram, email, and the browser (Bruin Cloud). Ask in plain English from any of them. Bruin answers from the same live data, no matter which surface you use.
How is Bruin different from dbt?+
dbt only handles SQL transformation. Bruin handles ingestion, transformation in both SQL and Python, orchestration, quality checks, column-level lineage, and an AI analyst on top - all in one platform with a Git-native CLI and no separate vendors to stitch together.
Does Bruin replace Fivetran?+
Yes. Bruin has built-in connectors covering APIs, databases, data warehouses, SaaS apps, cloud storage, webhooks, and event streams, with new sources added continuously. There's no need for a separate ingestion tool, and the same platform handles transformation and analytics on top of what it ingests.
Is Bruin an Airflow alternative?+
Yes. Bruin runs SQL and Python pipelines on a Git-native schedule with no separate orchestrator to host, scale, or maintain. Beyond what Airflow does, Bruin also handles ingestion across databases, warehouses, SaaS apps, files, APIs, and event streams, automated quality checks, column-level lineage, and an AI analyst on top. Teams move off Airflow to cut the ops overhead of a standalone scheduler and to get a single platform where data flows, runs, gets tested, and gets queried.
Does Bruin work with Snowflake, BigQuery, and Databricks?+
Yes, natively. Bruin connects to all major data warehouses (Snowflake, BigQuery, Databricks, Redshift, Postgres, ClickHouse, DuckDB, MySQL, SQL Server) and runs transformations directly inside them, so your data never leaves your infrastructure.
Does Bruin have an AI data analyst?+
Yes. Ask questions in plain English in Slack, Microsoft Teams, Google Chat, WhatsApp, Discord, Telegram, email, or Bruin Cloud. Bruin answers using your live pipelines, metadata, and quality state, so it won't respond from stale or broken data, and everyone in your organization gets the same answer to the same question.
Is Bruin open source?+
Yes. The Bruin CLI core is MIT-licensed and self-hostable. A managed cloud platform layer adds the AI analyst, AI dashboards, governance, scheduling, and team access controls. You can mix and match - start free with the open-source CLI, upgrade to the managed platform when you need it.
How fast can teams get started with Bruin?+
Minutes to first pipeline using the open-source CLI. Under two minutes to first dashboard from a chat prompt on the managed platform. No vendor onboarding, no professional services required.
Is Bruin SOC 2 compliant and enterprise-ready?+
Yes. Bruin is SOC 2 Type 2 certified, supports role-based access control, audit logs, VPC peering, and region selection. Transformations run inside your warehouse, so customer data never leaves your infrastructure. Single sign-on and provisioning are available on enterprise plans.
Can I self-host Bruin?+
Yes. The Bruin CLI is MIT-licensed and runs anywhere you can run a binary, including on-prem and air-gapped environments. The managed cloud adds the AI analyst, AI dashboards, scheduling, and governance on top, but you can stay fully self-hosted if you prefer.
How does Bruin handle data privacy with the AI analyst?+
Your raw data is never used to train any model. The AI analyst reads schema, metadata, and quality state, generates SQL, and runs that SQL against your warehouse. Only the results needed to answer the question pass through, and all model calls go through enterprise LLM endpoints with no-training agreements.
Does Bruin support Python pipelines, not just SQL?+
Yes. SQL and Python are first-class citizens. Write Python assets for machine learning feature engineering, custom ingestion logic, or anything SQL cannot express. Both run in the same DAG, share column-level lineage, and are tested with the same quality framework.
Do I have to use all of Bruin, or can I mix it with my existing tools?+
Each layer is independent, so you can adopt as much or as little of Bruin as you want. Keep Fivetran or Airbyte for ingestion and use only Bruin's SQL and Python transformation layer. Run dbt models side by side with Bruin assets. Point the AI analyst at a Snowflake, BigQuery, or Databricks warehouse populated by anything upstream. Run AI dashboards alongside Looker, Tableau, or Mode. Most teams start with one layer and expand from there.
Does Bruin work with my existing dbt, Airflow, or LookML repos?+
Yes. Bruin reads your existing pipelines and semantic layers directly: dbt models and tests, Airflow DAGs, LookML, Dagster and Prefect jobs, and any custom pipelines you maintain. It builds a semantic understanding of your tables, joins, metrics, and lineage on top of what's already there, so the AI analyst answers from your real definitions instead of guessing. You don't have to migrate to Bruin pipelines to get the AI layer working, and if you want the full platform later, you can adopt Bruin pipelines incrementally.
How hard is it to migrate from an existing data stack?+
Bruin is designed to coexist with what you already have. Most teams move incrementally: point a new pipeline at Bruin, then migrate existing assets at their own pace. The CLI is Git-native, so versioning, code review, and rollbacks work the same way they already do in your team.