Data Quality
Accurate data
at your fingertips
Build end-to-end data pipelines with high quality, alert on data accuracy issues, increase trust in your data, and make better decisions.
Trusted by forward-thinking teams
// stage.quality.preview

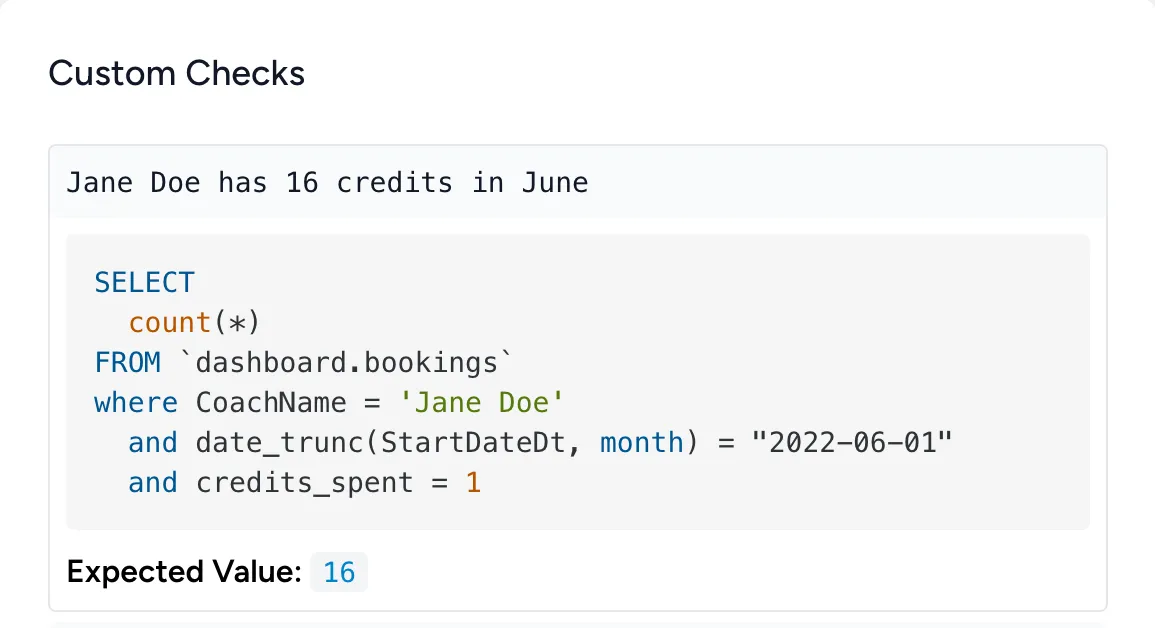
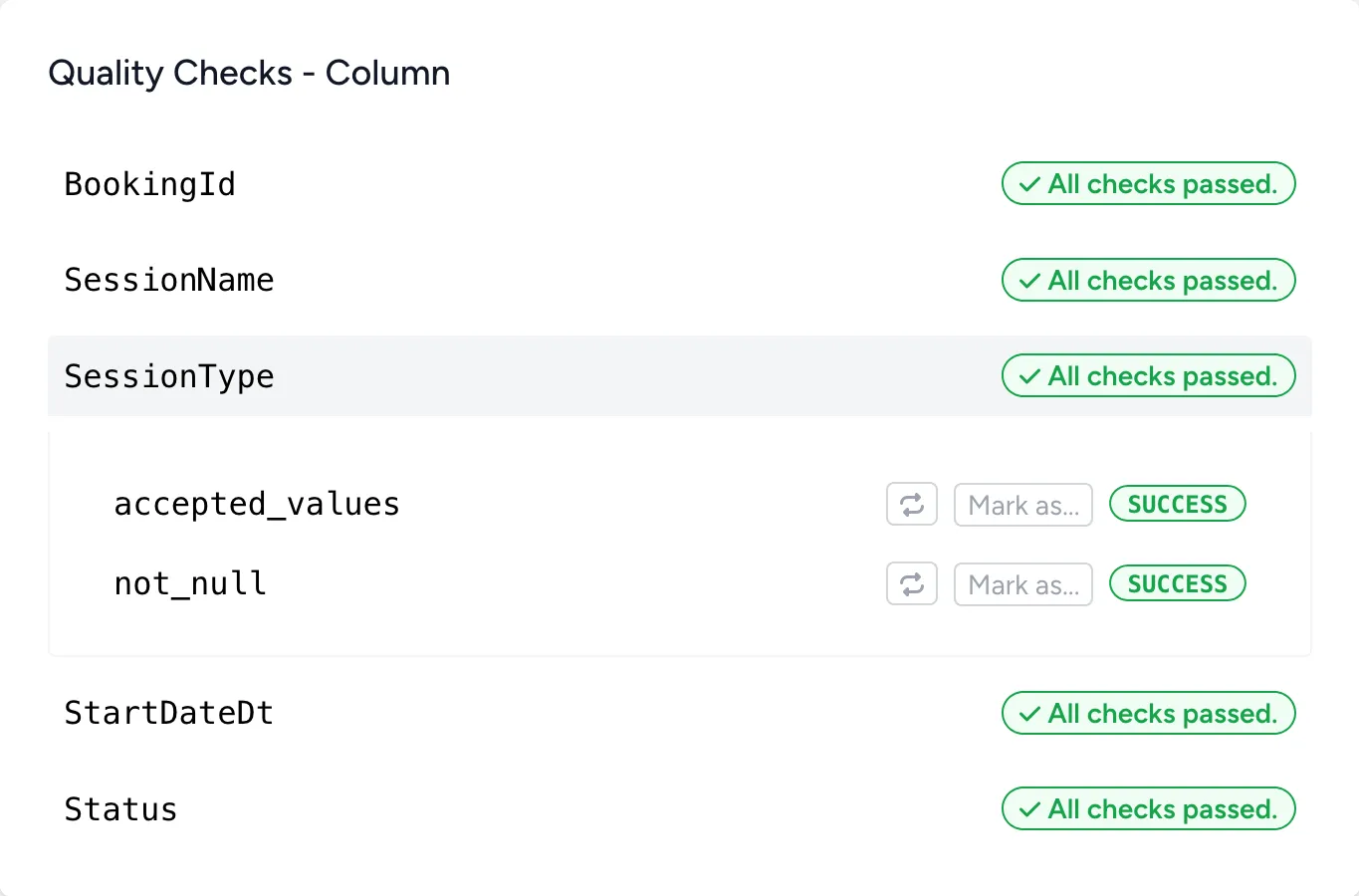
// stage.quality.checks
Quality checks on every run
Bruin executes all of your quality checks immediately after your transformation logic, allowing you to ensure the data is accurate after every execution.
- Multiple platforms
- Bruin supports all major data warehouses, databases, and query engines.
- Built on open-source
- Bruin's quality engine is part of the open-source Bruin CLI, allowing you to run everything locally.
- Built-in checks
- Bruin supports a variety of built-in quality checks, such as not_null, accepted_values, and more.
- Custom checks
- Going beyond the built-in checks, Bruin allows you to define custom quality checks in SQL.
// stage.quality.pipeline
End-to-end quality at every step
Bruin's built-in data quality capabilities are designed to be executed at every step of the pipeline: ingestion, transformation, reverse ETL and more. Make sure the data is accurate at every step.
- Blocking by default check.01
- Quality checks are designed to be treated as gates, meaning that if a check fails, the pipeline will not proceed.
- Non-blocking as optional check.02
- If you have long-running checks that are optional, you can mark them as non-blocking, allowing the pipeline to proceed even if the check fails.
- Templating in quality checks check.03
- Bruin supports templating in quality checks, meaning that you can use variables in your checks, and run checks only for incremental periods.
- Automated alerting check.04
- Failing quality checks will automatically send alerts to the configured channels, ensuring that you are always aware of the data quality issues.
name: raw.users
type: ingestr
parameters:
source_connection: postgresql
source_table: 'public.users'
destination: bigquery
columns:
# Define columns along with their quality checks
- name: status
checks:
- name: not_null
- name: accepted_values
values:
- active
- inactive
- deleted
# You can also define custom quality checks in SQL
custom_checks:
- name: new user count is greater than 1000
query: |
SELECT COUNT(*) > 1000
FROM raw.users
WHERE status = 'active'
AND created_at BETWEEN "{{start_date}}" AND "{{end_date}}"
Replace your entire stack
Every layer of your data infrastructure. One platform. Zero stitching.
All of this, in one platform.
Plug and play
Use one layer. Or stack them all.
Use any or every capability and save 10× on cost.
AI Dashboards · Agentic, self-updating
AI Analyst · Ask your data anything
Lineage · Column-level, automatic
Quality · Checks on every run
SQL & Python · Transformation + orchestration
Ingestion · thousands of connectors
Drag or tap a layer to toggle
Quick preview