Transformation & Orchestration
SQL & Python.
Same pipeline.
Multi-language data pipelines, native support for SQL & Python, and the ability to run both in the same pipeline.
Trusted by forward-thinking teams
/* @bruin
name: dashboard.bookings
type: bq.sql
owner: [email protected]
materialization:
type: table
depends:
- raw.Bookings
- raw.Sessions
- raw.Languages
- raw.Programmes
- dashboard.organizations
- raw.Teams
- dashboard.users
- dashboard.session_type_mapping@bruin */SELECT
bookings.Id AS BookingId,
sessions.Name AS SessionName,
dashboard.session_type_mapping(bookings.SessionType) AS SessionType
FROM raw.Bookings AS bookings
INNER JOIN raw.Sessions AS sessions
ON bookings.SessionId = sessions.Id
""" @bruinname: dashboard.coaches
image: python:3.12
instance: b2.xlarge
depends:
- dashboard.bookings@bruin """import os
import boto3
import pandas as pd
AWS_ACCESS_KEY_ID = os.getenv("AWS_ACCESS_KEY_ID")
AWS_SECRET_ACCESS_KEY = os.getenv("AWS_SECRET_ACCESS_KEY")
s3_client = boto3.client("s3", aws_access_key_id=AWS_ACCESS_KEY_ID, aws_secret_access_key=AWS_SECRET_ACCESS_KEY)
response = s3_client.get_object(Bucket="my-bucket", Key="files/coaches.csv")
status = response.get("ResponseMetadata", {}).get("HTTPStatusCode")
if status == 200:
print(f"Successful S3 get_object response. Status - {status}")
books_df = pd.read_csv(response.get("Body"))
print(books_df)
// stage.transformation.languages
Reality is multiple languages
Even though we love to stay inside SQL as much as possible, the reality is almost always multi-language. Bruin embraces the reality, giving you the right tools for multi-language pipelines.
- Multiple platforms
- Bruin supports all major data warehouses, databases, and query engines.
- Multiple languages
- Bruin supports both SQL and Python, allowing you to use the right language for the right job.
- Managed infrastructure
- Bruin executions happen on managed infrastructure, meaning you don't have to worry about the underlying infrastructure.
- Built-in quality checks
- Data quality checks go for both SQL and Python the same way, bridging the gap when it comes to quality.
// stage.transformation.infra
Focus on business logic
We have an opinionated take when it comes to infrastructure: teams should focus on business logic, not infra. We take care of the boring parts, so that you can focus on your business.
- Elastic, managed infra item.01
- Bruin provides an elastic infrastructure, allowing you to focus on the core business logic. Scale as you wish without worrying about the underlying infrastructure.
- Cross-language dependencies item.02
- Bruin builds your pipeline dependencies automatically, and allows you to define dependencies across languages for your assets.
- Analytics + AI/ML item.03
- Thanks to the unified infrastructure with multiple languages, you can easily combine analytics and ML / AI workloads in the same pipeline.
- Automated alerting item.04
- You will get alerted in case something goes wrong with your pipeline, regardless of the language you use.
""" @bruinname: dashboard.ltv
image: python:3.12
instance: b2.xlarge
depends:
- dashboard.bookings
- dashboard.coaches@bruin """import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from src.utils import fetch_customers_df
df = fetch_customers_df()
# LTV prediction model
X = df[['historical_spend', 'tenure_months', 'number_of_purchases']]
y = df['historical_spend'] * df['tenure_months'] / df['number_of_purchases']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = LinearRegression()
model.fit(X_train, y_train)
# Predict LTV
ltv_pred = model.predict(X_test)// stage.transformation.analysts
Built for data analysts.
Bruin enables data analysts to build production-grade data pipelines without any custom code.
SQL & Python Transformations
Bruin enables you to transform your data using SQL and Python without any custom code. SQL and Python transformations are executed in a serverless environment that scales with your data.
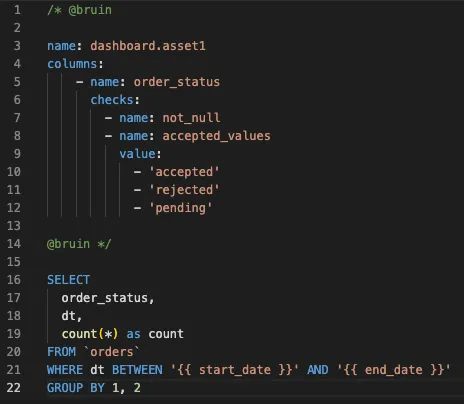
Ensure data quality
Using the built-in data quality checks enables building high-quality data assets.
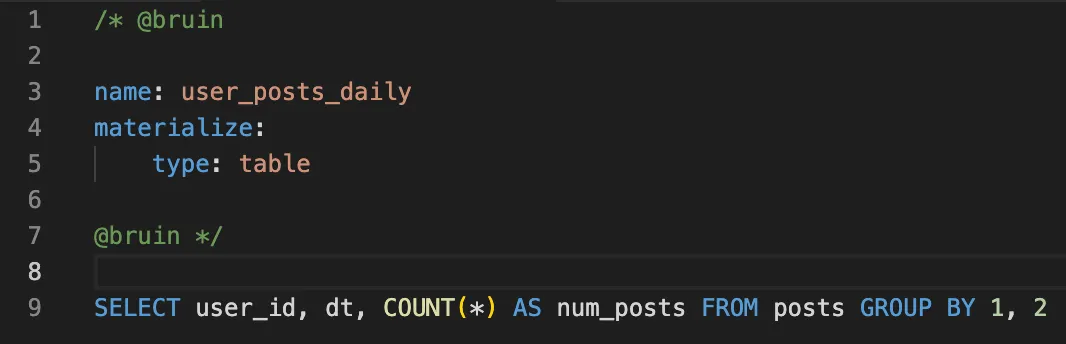
Automated Materialization
Just write the SELECT query and let Bruin take care of building the tables and views for you. It handles incremental updates as well as full refreshes.
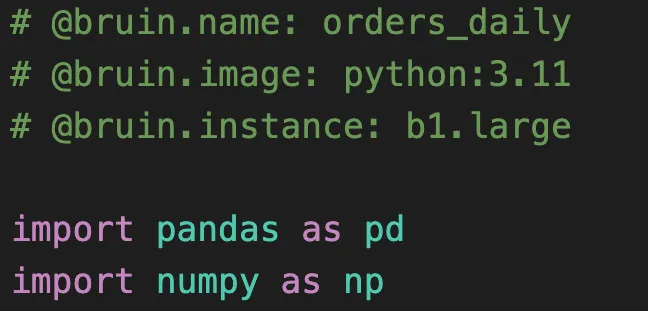
Managed infrastructure
All of your assets are built in isolated environments on a managed infrastructure. Bruin takes care of everything for a smooth development experience.
Replace your entire stack
Every layer of your data infrastructure. One platform. Zero stitching.
All of this, in one platform.
Plug and play
Use one layer. Or stack them all.
Use any or every capability and save 10× on cost.
AI Dashboards · Agentic, self-updating
AI Analyst · Ask your data anything
Lineage · Column-level, automatic
Quality · Checks on every run
SQL & Python · Transformation + orchestration
Ingestion · thousands of connectors
Drag or tap a layer to toggle
Quick preview