Segment vs Hightouch vs Census: Best Reverse ETL Tools 2026
Compare Twilio Segment reverse ETL, Hightouch, and Fivetran Census by customer profile ownership, governance, and workflow fit.
Arsalan Noorafkan
Developer Advocate
Quick answer for Segment vs Hightouch vs Census: use Hightouch when the warehouse is the source of truth and marketing needs audience activation. Use Fivetran Census when Fivetran already runs most of your data movement and you want reverse ETL under the same vendor. Use Twilio Segment when Segment already owns event collection, identity, profiles, and journeys. Use Bruin when activation has to sit beside governed pipelines, checks, lineage, Slack or Teams delivery, and AI agents.
Broader shortlist: the best reverse ETL tools in 2026 are Bruin, Hightouch, Fivetran Census, Twilio Segment, RudderStack, Polytomic, Omnata, GrowthLoop, DinMo, Multiwoven, Domo, Skyvia, Improvado, Airbyte, Workato, Hevo Activate, and Salesforce Data Cloud. If you mostly need warehouse-to-CRM or warehouse-to-marketing syncs, start with Hightouch, Fivetran Census, Segment, RudderStack, Polytomic, Omnata, GrowthLoop, DinMo, Skyvia, Improvado, or Domo depending on your stack. If you want activation to include governed pipelines, Python assets, scheduled AI agents, Slack or Teams delivery, and data workflows that can create tasks or recommendations, Bruin is the one to shortlist first.
Reverse ETL used to be a pretty narrow category: take modelled data from the warehouse and push it into Salesforce, HubSpot, Braze, Customer.io, Zendesk, an ads platform, or an internal database.
That still matters. A lot.
But in 2026, it is no longer the whole story. Data activation now includes three different jobs:
Classic reverse ETL - sync rows, traits, audiences, events, and objects from a warehouse into business apps.
Composable CDP activation - let marketing and growth teams build audiences and journeys on top of warehouse data.
Workflow activation - turn data into messages, reports, tasks, PRs, tickets, or agent-driven follow-ups inside Slack, Teams, GitHub, Linear, Jira, and the browser.
Those are related, but they are not the same buying decision.
We build Bruin, so obviously we know Bruin best. I will still try to be fair. If you only need a marketer-friendly audience builder with hundreds of destinations, Hightouch or GrowthLoop may be a better fit. If you are all-in on Salesforce, Data Cloud may be the path of least resistance. If you are Snowflake-only and care deeply about data staying inside Snowflake boundaries, Omnata is genuinely interesting.
But if your problem is broader than "sync this segment into a campaign tool", then the category changes.
Best overall for governed data + AI activation: Bruin, because reverse ETL sits beside ingestion, SQL/Python/R assets, quality checks, lineage, DAC, scheduled agents, and Slack/Teams/browser workflows.
Best composable CDP shortlist: GrowthLoop, DinMo, Twilio Segment, RudderStack, Salesforce Data Cloud.
Best BI / iPaaS-style alternatives: Domo, Skyvia, Improvado, Workato, Hevo Activate, Airbyte.
Best open-source angle: Bruin, Multiwoven, Airbyte, and older Grouparoo patterns.
The important thing: do not pick a reverse ETL tool only because it has the longest destination list. Pick it based on who owns activation, how governed the data needs to be, and whether the output is a field sync, an audience, a message, a task, or an agent workflow.
If your shortlist is Twilio Segment, Hightouch, and Fivetran Census, decide based on who owns activation and where the customer profile already lives.
The quick answer: Hightouch is usually the cleanest default when the warehouse is the thing everyone trusts. Fivetran Census is the easier procurement and operations story when Fivetran already runs the data movement layer. Twilio Segment makes sense when Segment is already the CDP profile and journey system.
Pick
When it fits best
Hightouch
Marketing, growth, or RevOps owns warehouse-native audiences, lifecycle syncs, ads activation, and CRM enrichment.
Fivetran Census
Your team already uses Fivetran for managed data movement and wants reverse ETL folded into the same vendor relationship.
Twilio Segment
Segment is already your event collection and customer profile layer, and the main job is CDP-style audience activation.
Bruin
The activation workflow needs governed pipelines, checks, lineage, Python assets, Slack or Teams delivery, and AI agents alongside the sync.
The short version: Hightouch is the warehouse-native marketing default, Fivetran Census is the Fivetran-stack default, and Segment is the CDP-profile default. Bruin becomes more relevant when the work is broader than audience sync and needs proper data engineering controls around it.
Governed activation with pipelines, checks, lineage, and AI agents
Bruin
Warehouse-to-Salesforce, HubSpot, ads, and lifecycle tools
Hightouch, Fivetran Census, Polytomic
Marketer-owned audience building and journeys
GrowthLoop, DinMo, Hightouch Customer Studio
Salesforce-first customer activation
Salesforce Data Cloud, Omnata, Hightouch
Snowflake-native Salesforce sync
Omnata
Event collection + profile activation
Twilio Segment, RudderStack
Open-source / self-hosted reverse ETL
Bruin, Multiwoven, Airbyte, Grouparoo patterns
BI plus activation in one platform
Domo
General cloud integration and no-code syncs
Skyvia, Workato, Hevo Activate
Marketing analytics plus activation
Improvado
This is closer to how buyers actually search. They do not only ask "which reverse ETL tool has the most connectors?" They ask "which tool fits our stack without creating another mess?"
A reverse ETL tool moves prepared data from a warehouse, lakehouse, or analytical database back into operational systems.
The usual destinations are:
CRMs like Salesforce, HubSpot, Pipedrive, or Attio
marketing platforms like Braze, Customer.io, Klaviyo, Marketo, Google Ads, Meta Ads, and TikTok Ads
support tools like Zendesk, Intercom, Freshdesk, and Gorgias
product databases and internal applications
spreadsheets, BI tools, and operational dashboards
Slack, Teams, Jira, Linear, GitHub, and other workflow tools
The old version of the category was very literal: warehouse table -> destination field.
The newer version is broader. Reverse ETL is becoming data activation. The warehouse calculates something useful, then the business acts on it. Sometimes that action is a CRM update. Sometimes it is an audience. Sometimes it is a Slack brief, a Teams report, a ticket, a PR, or an AI agent taking the first pass at the next step.
That is why this article includes both classic reverse ETL tools and data activation platforms.
The usual reverse ETL checklist is not enough anymore.
Yes, you still need connectors, mapping, scheduling, retries, incremental syncs, audit logs, and rate-limit handling. But the hard part is deciding where the activation workflow should live.
I would compare tools across seven questions:
What is the activation surface? CRM fields, ad audiences, marketing journeys, internal apps, Slack messages, Teams reports, tickets, PRs, or all of the above?
Who is the user? Data engineers, analytics engineers, marketers, sales ops, RevOps, customer success, product teams, or business users asking questions in chat?
Where does modelling happen? SQL in the warehouse, dbt, a vendor UI, Python assets, semantic models, or a CDP profile builder?
How governed is the handoff? Quality checks, lineage, field ownership, PII controls, audit logs, approval flows, and clear overwrite rules.
How custom can the destination be? Prebuilt connectors are nice until your actual destination is an internal API or a product database with weird write semantics.
How agent-friendly is the system? Can AI agents read the pipeline definition, inspect docs, query data, compare environments, and safely propose changes?
How much new infrastructure does it add? Another platform can be worth it, but only if the activation layer is important enough to justify the extra surface area.
That last question is where a lot of projects get painful.
Reverse ETL starts as "let's push churn score into Salesforce". Six months later, the team owns a sync platform, a warehouse model, a dbt job, an orchestration job, destination-side validation rules, a Slack alert, a spreadsheet of field ownership, and some script nobody wants to touch.
Bruin is not a classic reverse ETL vendor in the narrow sense. It is an open-source-first data platform with ingestion, SQL/Python/R assets, orchestration, quality checks, lineage, Bruin Cloud, an AI data analyst, scheduled agents, and MCP support.
That makes the activation pattern different.
In Bruin, you usually model the activation dataset as a normal asset, validate it, then either:
push it into an external destination with a Python asset
materialize it into a table for an app or internal service
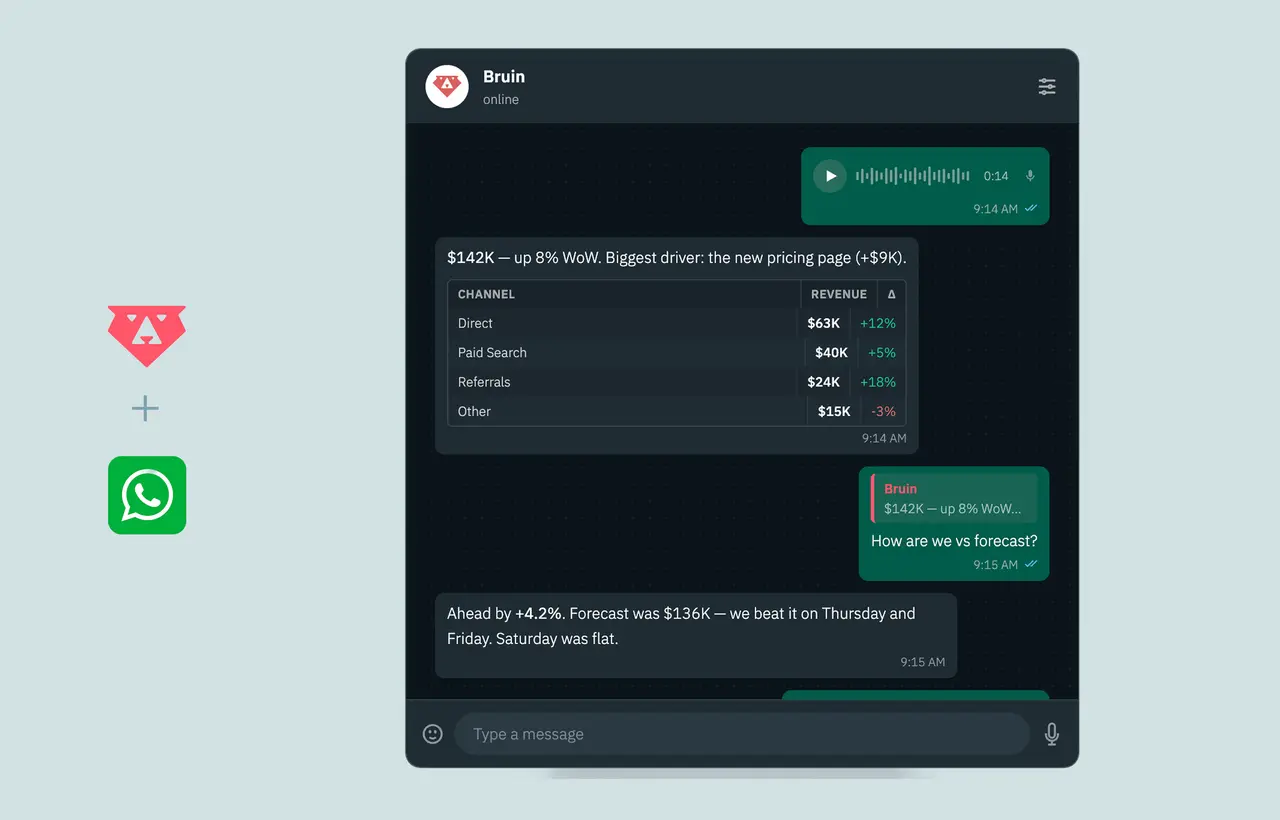
send a scheduled AI agent result into Slack, Teams, Discord, Google Chat, WhatsApp, Telegram, or email
let an AI analyst answer a question in Slack or Teams and turn the result into a follow-up task
use Bruin MCP so an AI agent in Codex, Claude Code, Cursor, or VS Code can read docs, query data, compare environments, build pipelines, and validate changes
That is classic reverse ETL plus a more modern "data to workflow" layer.
The practical difference: Bruin treats activation as part of the same pipeline system that produced the data. You do not have to export a segment into a separate reverse ETL UI, then remember which dbt model, scheduler, and alerting rule produced it. SQL, Python, metadata, checks, and lineage can live together.
A simple Bruin activation pipeline could look like this:
That matters for use cases where the destination is not just a SaaS field.
Examples:
customer success gets a daily Slack brief of accounts at risk, with reasons and suggested next actions
sales gets account health scores pushed to a CRM, but leadership gets a weekly Teams summary explaining what changed
marketing gets a scheduled agent that reviews GA4, GSC, warehouse revenue, and campaign data, then opens a PR or task when something is worth changing
product gets a table of recommendations materialized for the app, with checks and lineage attached to the upstream logic
data engineering gets an AI agent that can inspect runs and compare dev/prod output through Bruin MCP before a sync goes live
This is the part most pure reverse ETL tools do not really own. They are very good at "row in warehouse -> row in destination". Bruin is better when the activation output might be a row, a message, an answer, a chart, a ticket, or a code change.
Where Bruin wins
Open-source CLI and ingestr foundation
SQL, Python, and R assets in the same pipeline
Quality checks and lineage as part of the pipeline definition
Python assets for custom APIs, internal tools, and destinations that no connector vendor will prioritize
Scheduled agents for recurring insights and recommendations
Slack, Microsoft Teams, Discord, Google Chat, WhatsApp, Telegram, email, and browser surfaces for the AI analyst
MCP support for agentic data engineering workflows
Strong fit for small and mid-sized data teams that do not want five vendors just to move from raw data to action
Where Bruin is not the obvious pick
A marketing team wants a no-code audience builder and journey UI more than a data engineering workflow
You need hundreds of packaged reverse ETL destinations managed by a vendor UI today
Your whole activation strategy lives inside Salesforce Data Cloud or a marketing CDP
Best for: teams that want data activation to include pipelines, checks, lineage, AI analysts, scheduled agents, and workflow-native delivery - not only reverse ETL syncs.
Hightouch is still the default name people bring up when they say reverse ETL. Its product has expanded into composable CDP, customer studio, and AI decisioning, but the core idea is still warehouse-native activation: model customer data in the warehouse, then sync it into marketing, sales, ads, analytics, and internal tools.
Hightouch is especially strong when the buyer is marketing, growth, lifecycle, or RevOps, and the data team wants to keep the warehouse as the source of truth.
The platform has a big destination ecosystem, real-time and scheduled syncs, audience tooling, governance features, and a strong enterprise story around not storing customer data. It is also pushing hard into AI decisioning for marketing - deciding message, channel, timing, and personalization based on warehouse data and campaign feedback.
Where Hightouch wins
Mature reverse ETL destination coverage
Strong marketer-facing audience and activation UI
Composable CDP positioning is clear and well understood
Good fit for ads, lifecycle, CRM, and customer engagement activation
Enterprise security and private connectivity story
AI decisioning for marketing-specific use cases
Where Bruin compares well
Bruin is less of a packaged CDP and more of a governed data + workflow platform. If the activation is "send this modeled audience to Braze", Hightouch is probably ahead. If the activation is "model the data, validate it, run a Python handoff, explain the result in Slack, open a task, and let agents inspect the pipeline", Bruin is the broader system.
Best for: enterprise marketing and growth teams that want warehouse-native audience activation with a polished business-user UI.
Census was one of the original reverse ETL leaders. In 2025, Fivetran announced an agreement to acquire Census, which made the direction pretty clear: Fivetran wants to move governed data in both directions, not only into the warehouse.
That makes Census/Fivetran interesting for teams that already use Fivetran heavily. If Fivetran owns ingestion, managed connectors, and operational data movement, adding reverse ETL through the same vendor can simplify procurement and operations.
The Census model is familiar: define datasets from warehouse tables or queries, map fields into destinations, schedule syncs, monitor failures, and keep operational tools in sync with the warehouse.
Where Fivetran Census wins
Mature reverse ETL product history
Strong fit for teams already standardizing on Fivetran
Managed connector operations and enterprise procurement path
Good operational analytics framing
Natural choice if the buyer wants "one managed data movement vendor"
Where Bruin compares well
Bruin's advantage is that activation is not separated from the pipeline layer. You can ingest, transform, test, document, inspect lineage, and activate through the same repo-driven workflow. Fivetran Census is more attractive if you want managed data movement as a service and are happy with a vendor-managed activation layer on top of your existing modelling stack.
Best for: Fivetran-heavy teams that want managed reverse ETL without introducing another standalone vendor.
Segment's Reverse ETL is a natural extension of its CDP. It extracts data from the warehouse using a query and sends it into third-party destinations, Segment profiles, Twilio Engage, conversion APIs, analytics tools, and business apps.
This is a good fit if Segment is already your customer data foundation. The data activation workflow then becomes part of the same ecosystem that handles event collection, identity, profiles, Engage, and downstream routing.
Segment also has a broad destination story. Its public materials talk about 700+ or 750+ supported destinations depending on the page, so the exact number is less important than the category point: this is a CDP-scale integration network.
Where Segment wins
Strong CDP and customer profile ecosystem
Good fit for event-heavy customer data stacks
Reverse ETL can enrich profiles or send warehouse data to downstream destinations
Useful for marketing campaigns, conversion APIs, profile enrichment, and business-team access
Programmatic management via API and Terraform
Where Bruin compares well
Segment is strongest when the job is customer-data activation inside a CDP architecture. Bruin is stronger when the job starts with pipelines and ends in broader operational workflows: Slack answers, scheduled agents, Python assets, internal APIs, data quality gates, lineage, and agentic development through MCP.
Best for: teams already using Segment/Twilio as their CDP and wanting warehouse data to feed customer profiles and destination routing.
RudderStack is customer data infrastructure: event collection, warehouse-first pipelines, profiles, transformations, and activation. Reverse ETL is one part of that.
This makes it different from a pure reverse ETL vendor. RudderStack is most compelling when the same platform is collecting behavioural events, landing them in the warehouse, building profiles or audiences, and sending activation-ready data downstream.
Where RudderStack wins
Strong warehouse-first customer data infrastructure story
Good for teams that care about event pipelines and customer profiles
Reverse ETL works naturally with downstream marketing, sales, and support tools
Data transformation and data quality are part of the broader platform story
Stronger fit for product/event data than generic business-object syncs
Where Bruin compares well
Bruin is a better fit if your data platform is broader than customer event infrastructure. It can ingest and transform many business domains, run checks, expose lineage, and support AI analyst workflows in chat. RudderStack is a better fit when the warehouse is mostly powering customer data profiles and event activation.
Best for: product-led or event-heavy companies that want collection, identity/profile work, and activation in one customer data platform.
Polytomic is a general data sync platform. It covers ETL, ELT, CDC streaming, reverse ETL, and two-way syncs across warehouses, databases, business apps, spreadsheets, and APIs.
That generality is the point. Some teams do not want a CDP. They want to keep Salesforce, NetSuite, HubSpot, Postgres, Snowflake, Google Sheets, and internal APIs aligned without building brittle glue code.
Where Polytomic wins
Broad two-way data sync use cases
Useful beyond marketing activation
Good fit for RevOps, finance ops, sales ops, and operations teams
Handles SaaS apps, warehouses, databases, spreadsheets, and APIs
More operational-sync shaped than audience-builder shaped
Where Bruin compares well
Bruin is better when sync is one output of a governed pipeline. Polytomic is better when the central problem is keeping many operational systems synchronized. If the activation dataset needs quality checks, lineage, Python transformations, and AI-generated Slack/Teams reports around it, Bruin gives more of the upstream and workflow context.
Best for: teams with many operational syncs and two-way integration needs, especially outside pure marketing.
Omnata is one of the more opinionated tools in this list. It is built around Snowflake-native integration, with Snowflake Native Apps and plugins for systems like Salesforce.
That architecture matters. Omnata's pitch is not "we are another SaaS layer that moves your data". It is closer to: run the sync engine inside your Snowflake account, keep control within Snowflake boundaries, and sync directly between Snowflake and business applications.
For Snowflake + Salesforce-heavy companies, that is a serious argument.
Good fit for companies that want fewer external data movement services touching sensitive CRM data
Where Bruin compares well
Bruin is warehouse-flexible and workflow-flexible. It works across many platforms and makes activation part of the pipeline/agent workflow. Omnata is more specialized, and that specialization is exactly why some Snowflake enterprise teams will like it.
Best for: Snowflake-first teams, especially those syncing with Salesforce and wanting native-app-style security boundaries.
GrowthLoop is a composable CDP and marketing activation platform. It is built for marketers who want to use cloud data to create audiences, run journeys, optimize campaigns, and increasingly use AI agents for marketing decisions.
This is not just reverse ETL in the old sense. GrowthLoop is trying to own the marketing growth loop: audience creation, journey orchestration, insights, performance feedback, and AI-driven optimization.
Where GrowthLoop wins
Marketer-first composable CDP
Audience and journey orchestration
Strong cloud warehouse positioning
AI Studio and agentic marketing workflows
Good for enterprise marketing teams with cloud data already in place
Where Bruin compares well
GrowthLoop is much more specialized around marketing. Bruin is broader: data engineering, pipelines, AI analyst, scheduled agents, data quality, lineage, and activation workflows across teams. If the buyer is growth marketing and the use case is campaigns, GrowthLoop deserves a look. If the buyer is the data team trying to create a governed activation backbone across the company, Bruin is a better starting point.
Best for: marketing teams that want composable CDP, journeys, and AI optimization on top of warehouse data.
DinMo is another warehouse-native / composable CDP vendor, with a clear focus on marketing activation. It positions itself around letting marketers activate customer data directly from the warehouse without heavy engineering involvement.
It is especially relevant for teams that want a business-user-friendly activation layer but do not want to copy all customer data into a monolithic CDP.
Where DinMo wins
Marketer-friendly warehouse-native activation
Good fit for audience building and campaign activation
Strong BigQuery and Snowflake positioning
Clear composable CDP story
Useful when marketing self-service is the priority
Where Bruin compares well
Bruin does not try to be a marketer-first CDP UI. It is stronger when activation needs to sit beside data pipelines, quality checks, lineage, Python code, scheduled reports, and AI analyst workflows. DinMo is stronger when the main question is "can marketing activate warehouse audiences without waiting for engineering?"
Best for: marketing teams that want a warehouse-native CDP and a fast self-service activation layer.
Multiwoven is the strongest open-source reverse ETL entrant in the current shortlist. It is built for syncing customer data from warehouses into business tools, with self-hosting and open-source control as the main draw.
If you want something closer to Hightouch/Census but open-source and self-hosted, Multiwoven is worth evaluating.
Where Multiwoven wins
Open-source reverse ETL
Self-hosted control
Good for teams that do not want SaaS data movement infrastructure
Connector ecosystem is growing
Extensible protocol for custom destinations
Where Bruin compares well
Multiwoven is focused on the reverse ETL layer. Bruin includes the upstream pipeline pieces too: ingestion, transformation, checks, lineage, orchestration, and AI workflows. If you only want open-source reverse ETL, Multiwoven may be a cleaner fit. If you want an open-source-first data platform where reverse ETL is one pattern, Bruin is broader.
Best for: teams specifically looking for open-source reverse ETL and self-hosted activation.
Grouparoo was one of the early open-source reverse ETL tools. Airbyte acquired Grouparoo in 2022, and the original Grouparoo site still describes open-source syncing from warehouses into business tools.
I would be careful shortlisting it for a new 2026 implementation without checking current project activity and roadmap. It is historically important, and some teams may still run it, but it is not the tool I see most often in fresh evaluations anymore.
Where Grouparoo wins
Open-source heritage
Code-config workflow
Self-hosting and privacy story
Useful reference point for reverse ETL patterns
Where Bruin compares well
Bruin is actively positioned around modern pipeline development, MCP, AI agents, and workflow-native data activation. Grouparoo is more of a classic reverse ETL framework.
Best for: existing Grouparoo users or teams specifically exploring the older open-source reverse ETL pattern.
Salesforce Data Cloud is not a reverse ETL tool in the usual vendor-category sense, but it absolutely competes for Salesforce activation budgets.
If the activation destination is Salesforce, and especially if the company is already deep into Sales Cloud, Service Cloud, Marketing Cloud, Commerce Cloud, Flow, Einstein, Agentforce, and the rest of the Salesforce ecosystem, Data Cloud can become the default answer.
The interesting part is zero-copy and bidirectional data access. Salesforce positions Data 360 / Data Cloud as a way to federate or share data with warehouses like Snowflake, Databricks, Redshift, and BigQuery, then use that data for AI-powered insights, personalization, automation, and agent recommendations inside Salesforce applications.
Where Salesforce Data Cloud wins
Native Salesforce ecosystem activation
Strong fit for Salesforce workflows, Flows, AI, automation, and customer profiles
Zero-copy and federation patterns reduce some duplication
Governance lives close to Salesforce users and admins
Sensible path if Salesforce is already the operational centre
Where Bruin compares well
Bruin is neutral. It can push data to Salesforce, explain it in Slack, run checks before activation, and support non-Salesforce workflows. Data Cloud is strongest when Salesforce is the whole activation universe. Bruin is stronger when activation crosses data engineering, product, marketing, support, finance, and internal tools.
Best for: Salesforce-first enterprises where activation should happen inside Salesforce applications and automation.
The tools above are the main ones I would put in a serious shortlist, but the search results for this category also include a few adjacent platforms. Some are strong for a specific buyer, some are better understood as alternatives rather than direct replacements.
Domo is more of an integrated BI and data platform than a dedicated reverse ETL product. It makes sense when the company already wants BI, data apps, modelling, integration, and operational workflows in one commercial platform. The tradeoff is obvious: you are buying into a large platform, not adding a small activation layer.
Best for: teams that want BI and activation together, and are comfortable with a broader enterprise platform.
Skyvia shows up because it is a broad cloud data integration platform with many business-app connectors, no-code workflows, backup, query, and sync features. It is less "modern data stack engineer writing activation models" and more "business-friendly cloud integration tool".
Best for: teams that want a straightforward no-code integration platform for common SaaS and database syncs.
Improvado is strongest in marketing data operations. If your reverse ETL use case is tied to paid media, campaign performance, marketing analytics, and bidirectional marketing data flows, it belongs in the evaluation.
Best for: marketing teams that need inbound connector coverage and activation in one marketing data platform.
Workato is an iPaaS and automation platform. It can move data into operational workflows, but the product centre is broader automation rather than warehouse-native reverse ETL. That can be a good thing if the workflow spans approvals, app actions, notifications, and branching logic.
Best for: operations teams that need app automation more than warehouse-native activation.
Hevo Activate makes sense if you are already in the Hevo ecosystem and want reverse ETL as an extension of managed ELT. The appeal is vendor consolidation. The tradeoff is that you are choosing the Hevo stack, not a neutral activation layer.
Best for: Hevo customers who want to add activation without bringing in another vendor.
Airbyte is primarily known for open-source ELT. It can support activation patterns depending on destinations and configuration, but I would not evaluate it the same way I would evaluate Hightouch, Census, or Multiwoven. It is a connector platform first.
Best for: technical teams that already like Airbyte and want open-source connector infrastructure.
Matillion and Astera are data integration / transformation platforms that can overlap with reverse ETL in enterprise evaluations. They are more relevant when the buyer wants broad data integration, transformation, and enterprise workflow capabilities, not just customer activation.
Best for: enterprises evaluating larger data integration platforms, not teams looking for a focused reverse ETL layer.
Pick Bruin if you want data activation to be part of a governed data platform, with SQL/Python/R assets, ingestion, checks, lineage, scheduled agents, chat-based AI analysts, and MCP-friendly agent workflows.
Pick Hightouch if marketing activation and composable CDP workflows are the main reason you are buying.
Pick Fivetran Census if you already trust Fivetran as your managed data movement layer and want reverse ETL folded into that strategy.
Pick Twilio Segment if Segment is already your CDP and warehouse activation should feed profiles, Engage, and Segment destinations.
Pick RudderStack if event collection, customer data infrastructure, profiles, and activation are one combined problem.
Pick Polytomic if the problem is broad two-way sync across SaaS apps, databases, warehouses, spreadsheets, and APIs.
Pick Omnata if you are Snowflake-first and want Snowflake-native integration, especially with Salesforce.
Pick GrowthLoop if enterprise marketing wants composable CDP, journeys, and AI optimization on warehouse data.
Pick DinMo if marketing wants warehouse-native self-service activation without a heavy CDP migration.
Pick Multiwoven if you specifically want open-source reverse ETL and self-hosted control.
Pick Grouparoo / Airbyte if you already use it or want to study the older open-source reverse ETL approach.
Pick Salesforce Data Cloud if Salesforce is the operational system of record and you want activation inside Salesforce apps, automation, and agents.
Pick Domo, Skyvia, Improvado, Workato, Hevo, Airbyte, Matillion, or Astera when the buying question is broader than reverse ETL and includes BI, iPaaS, marketing data operations, no-code cloud integration, or enterprise data integration.
When the warehouse knows something important, what should happen next?
Sometimes the answer is still a sync:
update churn_risk in Salesforce
send a segment to Braze
enrich HubSpot with product usage
sync conversion events to Meta Ads
update an internal product database
But sometimes the answer is not a sync at all:
send a daily risk brief to customer success in Slack
schedule a weekly revenue explanation for leadership in Teams
open a Linear task when activation data fails a freshness check
ask an AI analyst why a metric moved, then attach the SQL and chart to a GitHub issue
let a scheduled agent review GA4 + GSC + warehouse data and open a PR when a page needs a measurable update
That second group is where Bruin is different.
Bruin's scheduled agents can run on a cadence and deliver insights, numbers, charts, and recommended actions to the tools where teams already work. Bruin MCP lets coding agents inspect Bruin docs, query data, compare environments, and build pipelines from an editor. Python assets let engineers call whatever destination API the business actually uses.
So the activation destination can be a CRM, but it can also be a conversation, a task, a repo, an internal app, or a human review step.
Honestly, that feels closer to how companies actually work.
Even if you pick the most AI-native tool in the world, the warehouse model still has to be boring and trustworthy.
A good activation model should have:
one row per target entity
explicit grain
stable identifiers
accepted values for enums and status fields
freshness checks
ownership metadata
clear overwrite rules
replay and backfill behaviour
lineage back to the source models
auditability for what was sent and when
For example:
select
account_id,
owner_email,
health_score,
risk_bucket,
next_best_action,
reason_code,
generated_at
from mart.customer_success_playbook_actions
Then validate the obvious stuff:
account_id is not null
one row per account_id
risk_bucket is one of low, medium, high
generated_at is fresh
owner_email exists for all high-risk accounts
If that dataset is wrong, every downstream tool becomes a faster way to spread bad decisions.
This is why I like keeping activation close to the pipeline system. The thing that calculates the recommendation should also declare what "correct" means before another system acts on it.
That loop can produce a warehouse table, a CRM update, a Slack answer, a scheduled Teams report, a Python API call, or an agent-created task.
The teams that usually get the most value from Bruin are:
small data teams trying to avoid a five-vendor stack
companies that need ingestion, transformation, quality, lineage, and activation together
teams that want open-source CLIs locally and managed governance in cloud
companies where Slack, Teams, WhatsApp, Discord, or browser workflows matter more than another dashboard
data teams experimenting with AI agents for pipeline development, monitoring, and action-taking
engineering teams with custom destinations that will never appear on a connector roadmap
The more your activation workflow looks like "business-user audience builder", the more you should compare Bruin with Hightouch, GrowthLoop, DinMo, Segment, and Census carefully.
The more it looks like "data engineering plus governed workflows plus AI agents", the stronger Bruin gets.
For classic warehouse-to-SaaS syncing, Hightouch, Fivetran Census, Polytomic, Omnata, and Multiwoven are the most direct shortlist. For broader governed activation with pipelines, checks, lineage, AI analysts, scheduled agents, and workflow delivery, Bruin is the stronger fit.
Reverse ETL is the movement pattern: prepared data leaves the warehouse and updates an operational system. Data activation is the business outcome: that data causes something useful to happen. The output might be a CRM field, an ad audience, a Slack message, a Teams report, a Linear task, or an agent-created PR.
Bruin can support reverse ETL patterns through SQL/Python/R assets, Python API calls, warehouse materialization, scheduling, checks, and lineage. It is broader than a classic reverse ETL tool because it also covers ingestion, transformation, quality, DAC, AI analysts, scheduled agents, and MCP-based data engineering workflows.
Bruin, Multiwoven, Airbyte, and Grouparoo-style implementations are the main open-source or open-source-first options to know. They are not identical: Bruin is a broader data platform, Multiwoven is focused on reverse ETL, Airbyte is mostly connector infrastructure, and Grouparoo is more of an older reverse ETL pattern.
Usually, yes. dbt can model activation tables, but it does not usually own the handoff into Salesforce, HubSpot, Braze, Slack, Teams, ads platforms, or internal APIs. You still need a sync layer, Python asset, API job, or workflow agent to make the model operational.
If marketing needs self-service audience building, journeys, identity, and campaign activation, evaluate GrowthLoop, DinMo, Hightouch, Segment, and Salesforce Data Cloud. If the data team owns the pipeline and wants governed activation across multiple teams, evaluate Bruin, Hightouch, Census, Polytomic, Omnata, and Multiwoven.
If you are comparing Twilio Segment reverse ETL with Hightouch vs Census, start with the source of truth. Hightouch is usually the best fit for warehouse-native marketing activation. Fivetran Census is better when you already rely on Fivetran and want ingestion plus reverse ETL under one managed data movement vendor. Twilio Segment is better when Segment already collects the events, owns the customer profile, and the team wants CDP-style audiences and journeys.