dlt Alternatives: Bruin, Airbyte, Sling, Meltano, and Fivetran Compared
A practical comparison of dlt alternatives for data ingestion: Bruin CLI, ingestr, Airbyte, Sling, Meltano, and Fivetran, including a MongoDB to Postgres benchmark.
Arsalan Noorafkan
Developer Advocate
Quick answer: dlt is a decent Python library for loading data. The problem is that a Python loading library is often the wrong abstraction for production ingestion. Pick Bruin CLI when ingestion should live inside a real pipeline with assets, materialization, quality checks, lineage, environments, and data diffs. Pick ingestr when the job is a direct source-to-destination sync and you want a fast CLI instead of another Python project. Pick Airbyte when you want a connector platform and UI. Pick Sling when you want a focused data movement CLI. Pick Meltano when you want Singer-based ELT. Pick Fivetran when you want managed ELT and are willing to pay for the abstraction.
The useful distinction is this:
dlt is a Python library for building data loading pipelines.
Bruin CLI is a pipeline framework: assets, dependencies, materialization, quality checks, lineage, environments, validation, data diff, and run orchestration.
ingestr is Bruin's open-source ingestion engine and standalone CLI for moving data from sources to destinations.
Airbyte is a connector platform.
Sling is a data movement CLI and platform.
Meltano is an open-source ELT platform built around Singer taps and targets.
Fivetran is a managed automated data movement platform.
That category difference matters. Bruin is not the "no Python" answer to dlt. Bruin supports custom Python assets too. The difference is that Python is not the whole product. In Bruin, custom Python can be one governed asset in a pipeline, with dependencies, secrets, materialization, checks, and lineage around it. That is a better boundary than "here is a Python script, good luck operating it."
The author works at Bruin. The view here is opinionated, but the comparison is meant to be useful.
dlt, short for data load tool, is an open-source Python library for loading data from messy sources into structured datasets. It gives Python interfaces for extraction, loading, inspection, schema evolution, and incremental loading.
That is a real use case. If you have a weird API, custom pagination, strange auth, or business-specific extraction logic, writing Python can be the right answer.
dlt is strongest when:
You want a Python library, not a platform.
Your source is custom enough that a connector abstraction gets in the way.
Your team is happy to own the runtime, deployment, scheduling, secrets, monitoring, and downstream model contracts.
You want to build the ingestion application yourself.
The part I do not like is when dlt becomes the center of the data stack. A Python loading library should not be the place where you explain ownership, asset quality, column contracts, lineage, environments, data diffs, and operational policy. You can bolt those things on, but then the "lightweight" library starts turning into a homegrown platform.
Look for a dlt alternative when one of these is true:
You do not want a Python application for every routine sync.
You want custom Python ingestion, but you also want automatic materialization into a warehouse.
You want ingestion to sit beside SQL models, Python transforms, quality checks, and lineage.
You want a CLI and Git workflow, not a pile of deployment glue.
You want AI agents to inspect, change, run, and validate pipelines using documented commands.
You want fewer hidden state and destination bookkeeping tables to reason about.
You need a UI or managed connector platform instead of code.
The important correction: "I need custom Python ingestion" is not a reason to rule out Bruin. Bruin supports Python assets and materializes returned data automatically.
Bruin CLI is the best dlt alternative when you want to keep code-first data engineering but stop treating ingestion as a loose Python app.
Bruin projects are built from assets. Assets can be SQL files, Python files, R files, ingestr assets, seeds, sensors, dashboards, and more. You run them with bruin run, validate them with bruin validate, format them with bruin format, inspect lineage with bruin lineage, and compare outputs across environments with bruin data-diff.
That means the unit of work is an asset in a pipeline, not a script someone remembers to deploy.
Bruin supports custom Python assets. A Python asset can define a materialize() function and return a pandas dataframe, Polars dataframe, PyArrow table, list of dicts, generator of dicts, or generator of Arrow tables. Bruin then materializes that output into the configured destination.
That is the key difference from dlt:
dlt gives you a Python loading library.
Bruin gives you Python as a pipeline asset with materialization, secrets, dependency isolation, quality checks, and lineage.
Bruin uses uv under the hood for Python dependency management. You can use pyproject.toml with uv.lock, or a requirements.txt file. You can also run different Python versions in different isolated assets.
For large API pulls, the generator path is especially important. You do not need to hold the whole dataset in memory. Bruin writes the batches to Arrow and loads them to the destination.
Under the hood, Bruin runs the Python asset, stores returned data as Arrow memory-mapped files, and uses ingestr to load that data into the destination. So Bruin and ingestr are not competing pieces. Bruin is the pipeline layer. ingestr is the ingestion and loading engine.
ingestr is the answer when the ingestion job is not custom.
If the task is "copy MongoDB to Postgres", "sync Postgres to BigQuery", "load Google Sheets into Snowflake", or "move this source table incrementally", I do not want to write Python. I want a command or a declarative asset.
ingestr inside Bruin is a pipeline asset with metadata, dependencies, schedules, environments, checks, and lineage around it.
Bruin Python assets are for custom ingestion logic that still needs automatic materialization and pipeline governance.
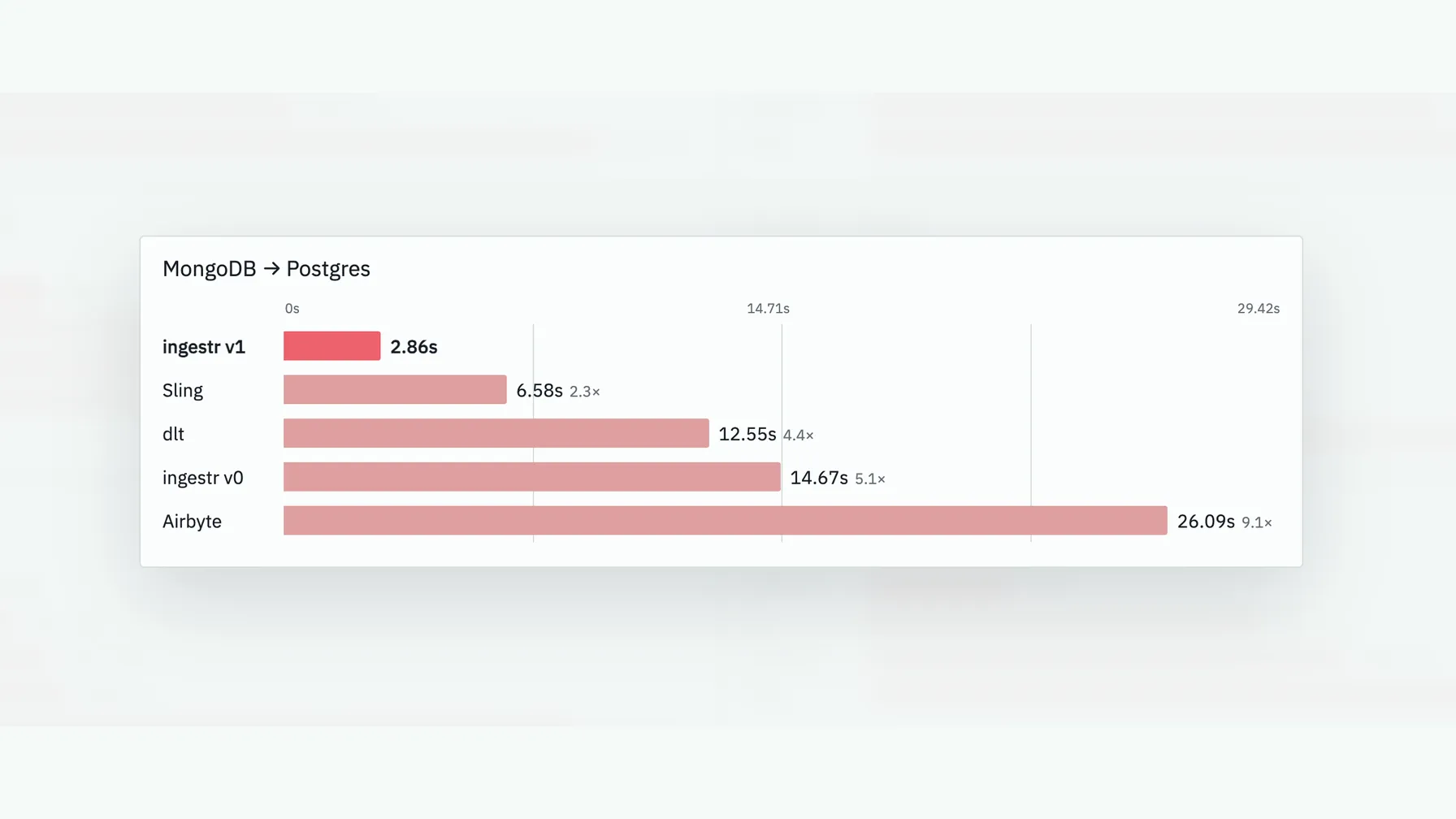
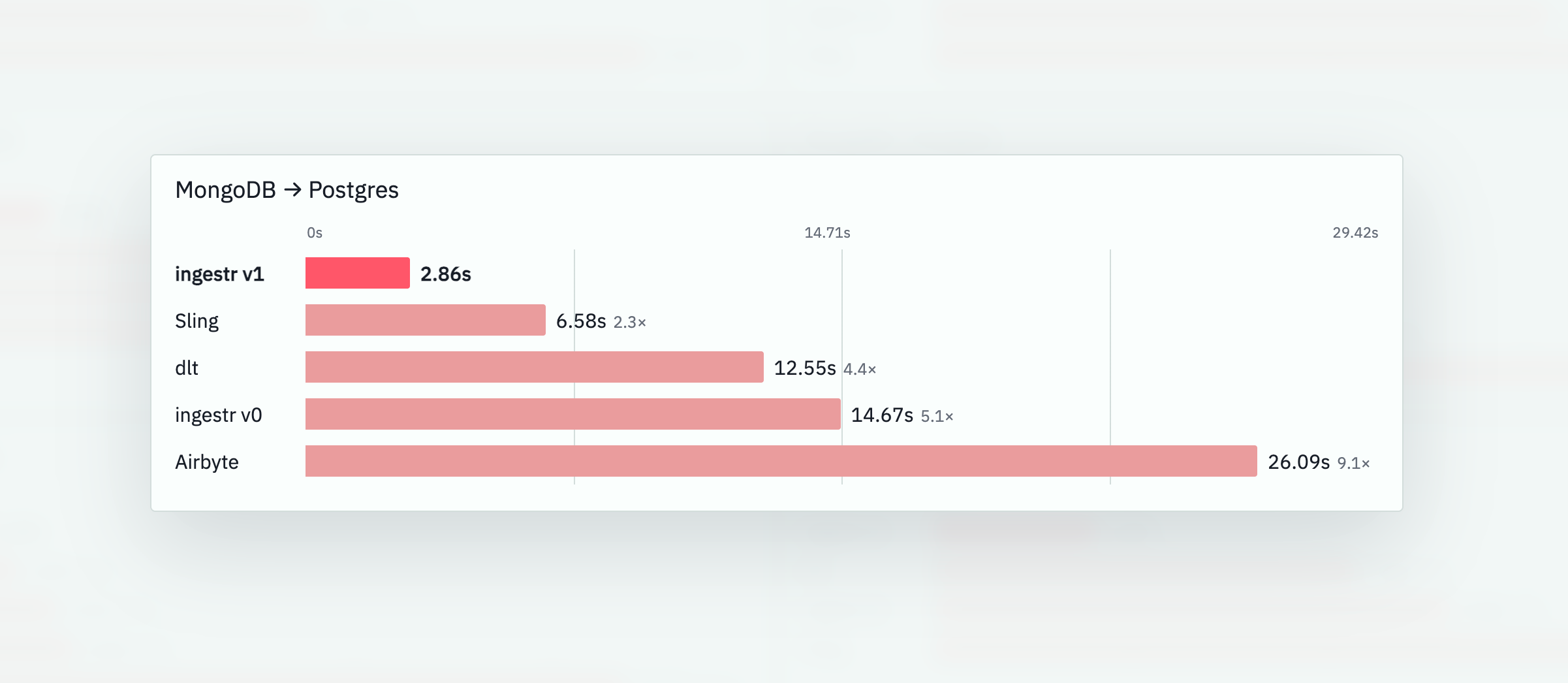
In the MongoDB to Postgres benchmark published in the ingestr repo, ingestr v1 completed the run in 2.86 seconds, compared with 6.58 seconds for Sling, 12.55 seconds for dlt, 14.67 seconds for ingestr v0, and 26.09 seconds for Airbyte. Benchmarks are workload-specific, but this is exactly the kind of routine source-to-destination movement where a compiled CLI should beat a Python library or heavier connector platform.
My opinion: for normal ingestion, dlt is too much Python and not enough pipeline. For strange custom ingestion, dlt is reasonable. For production data work, Bruin gives you a better place to put that Python.
This is another place where the abstraction matters.
Bruin MCP exposes Bruin CLI to AI agents. The docs describe it as a way for agents to query data, compare tables, ingest data, and build pipelines using Bruin. That gives an agent a stable set of commands and documentation:
bruin run to execute assets
bruin validate to catch definition issues
bruin lineage to inspect dependencies
bruin data-diff to compare outputs
ingestr assets for source-to-destination loading
Python assets for custom materialized logic
An AI agent can work with a Bruin project because the project has assets, metadata, checks, environments, and commands. With dlt, the agent is mostly editing Python code and hoping the surrounding deployment conventions are discoverable.
That is not a small difference. Agents need structure. A folder of Python ingestion code is flexible, but flexibility is not the same as operability.
Airbyte is the opposite end of the spectrum from dlt. dlt is a Python library. Airbyte is a connector platform.
Airbyte is useful when connector breadth and UI-driven setup matter. It is a better fit than dlt when analysts or analytics engineers need to configure syncs without writing code.
Choose Airbyte over dlt when:
You want a UI for setting up and monitoring syncs.
You need broad SaaS connector coverage.
You are willing to run or buy a connector platform.
You want connector management to be a platform concern, not a Python package concern.
Choose dlt over Airbyte when:
You need code-level extraction control.
You do not want to operate Airbyte infrastructure.
Your source logic is unusual enough that the connector abstraction gets in the way.
Choose Bruin over both when you want a code-first pipeline project where routine ingestion, custom Python, SQL transforms, quality checks, lineage, and data diff live together.
Sling is closer to ingestr than to dlt. It is a data movement CLI with a platform around it. The CLI supports quick ad hoc runs through flags and repeatable replication through YAML or JSON.
Choose Sling over dlt when:
You want a CLI rather than a Python library.
Your work is mostly database-to-database, file-to-database, or API-to-database movement.
You want a compact movement tool without adopting a broader pipeline framework.
Choose dlt over Sling when:
You need custom Python extraction logic.
You want library-level control over resource definitions and loading behavior.
Choose Bruin when you want the CLI experience but also want pipeline-level governance around it.
Fivetran is the managed option. It is not trying to be a Python library or local CLI. It is a hosted data movement platform with many pre-built connectors and managed operations.
Choose Fivetran over dlt when:
You want vendor-managed connectors.
You want less internal ownership of extraction logic.
You can justify the spend.
You prefer a commercial support path over maintaining ingestion code.
Choose dlt over Fivetran when:
You need custom logic that does not fit a managed connector.
You want open-source control.
You do not want managed ELT costs.
Fivetran is often the right answer when ingestion is a buying decision. dlt is often the right answer when ingestion is an engineering decision. Bruin is for teams that want engineering control without letting every ingestion job turn into a separate little application.
dlt uses state to support incremental loading and resumability. The dlt docs describe incremental loading as requiring tracking which increments have been loaded. The destination can also include internal tables such as _dlt_pipeline_state, which stores pipeline state and checkpoints.
That design is understandable. It is also another operational surface.
Stateful ingestion can become annoying when jobs move between environments, when destination bookkeeping tables confuse downstream users, or when an interrupted run leaves the next run depending on implementation details you did not mean to expose.
Bruin and ingestr are more opinionated. For common syncs, the preference is that the run is understandable from the asset definition: source, destination, strategy, incremental key, interval, columns, and schema. For custom Python, Bruin still gives you materialization and pipeline metadata so the output is not just a side effect of a script.
That is the critique of dlt in one sentence: it is flexible, but too much of the production shape still lives outside the library.
dlt is not useless. It is a good library for some custom Python ingestion jobs.
But I would not build a data platform around it. It puts too much emphasis on Python loading code and not enough on the things that make pipelines safe to operate: asset boundaries, materialization, checks, lineage, environments, validation, data diff, and agent-readable workflows.
Bruin's bet is different. Use ingestr when ingestion should be a command. Use Bruin Python assets when ingestion truly needs custom Python. In both cases, put the work inside Bruin CLI so it becomes part of a governed pipeline instead of another script with a scheduler attached.



{kind=link}