We have rebuilt ingestr from the ground up to be faster, more reliable, and easier to use. Here is how we did it and what it means for your data pipelines.
Burak Karakan
Co-founder & CEO
I have always hated how weird the data ingestion tooling was. There have been a lot of solutions, but none of them fit the bill:
There are paid tools that were driven by the UI: fair, but UI-driven workflows suck for proper data pipelines.
There are open-source alternatives that are mainly driven by UI (looking at you, Airbyte): same problems as the paid ones + more stuff to host now.
There are libraries that try to make it easy to build it yourself, such as dlt, but in the end you are writing custom code to ingest data.
In the end, what we thought was such an obvious form factor for data ingestion, the CLI, was not really available. That's why we set out to build ingestr in early 2024. The goal was to create a CLI tool that would be opinionated, and would be the easiest way to ingest data. You point it to a source URI, give it a destination URI, and let ingestr move the data for you.
ingestr ended up being quite a successful open-source project: 3.5k stars, hundreds of orgs running it internally, quitely humming in the background. We have also integrated it into Bruin CLI nicely, which enabled the true end-to-end data pipeline workflows, all the way from ingestion to transformation to dashboards.
However, over time, our approach started showing its shortcomings. That's why we have rebuilt ingestr from scratch, migrating it from Python to Go. I would like to share some of the reasoning in this post.
ingestr was built in Python. We have done that because we wanted to prototype quickly and see if the idea was worth pursuing. We started using dlt at the time, which was in its very early versions and we thought we might benefit from their integrations to build out further capabilities into a CLI. We built out the first version over a weekend, together with my co-founder Sabri, and got it out quickly.
Over time, ingestr turned out to be useful, but rather slow and resource-heavy on large workloads. This was due to a couple of things, but mainly boiling down to two major problems:
Python is a slow language. When dealing with a lot of data, trying to stay high-level, it is hard to squeeze performance out of it.
dlt, especially in its early versions, was really slow. This meant that no matter what we do, we would essentially be bound by how fast dlt could shift things around.
As we grew as a company and started servicing larger customers, with larger datasets that needed to be moved around quickly, we would fail to reach the quality bar we wanted to hit due to these problems. ingestr worked fine, but it wasn't fast enough. Or at least, we thought it could have been much faster.
ingestr is a CLI built with Python. As nice the ecosystem is in the Python land, distributing a command-line tool that would be executed on people's devices, with varying specs, operating systems, and more importantly, Python versions, is a nightmare. Things work in weird ways: there are compatibility issues, the niceties of the language, such as stricter type hints, cannot be used without breaking backwards compatibility, and debugging why things don't work becomes almost impossible. Coming from a Go-heavy world, this was quite a challenge to get used to.
This also meant that certain libraries would need to have compatible builds for the architectures that we needed to support, and that meant we couldn't just distribute a single version of the CLI. Instead, we would have to do things like "oh, if you need Oracle, you need to install it as ingestr[oracle] instead" kinds of things. These might be acceptable for Python folks, but we didn't want to have to give out a leaflet just to install a CLI.
Part of that was a design decision we made early on: ingestr was going to be a single CLI that included everything. It should just work out of the box. Turns out this wasn't the right way to build Python projects.
The upgrades became harder and harder with every new dependency. dlt had quite a few breaking changes during its earlier versions, understandably, as it was v0 software when we started using it. Every other DB driver we brought in would break in mysterious ways, and we would have to find ways of vendoring the code ourselves. This meant that as the surface area grew for ingestr, we were moving slower and slower. Building ingestr v0 was pre-agents, which meant that we actually had to accept all these dependencies.
If I was building it from scratch, in Python, today, I might seriously consider generating the hell out of every little dependency. I am not sure if that would work, but I would consider it. Anyway, I am digressing.
ingestr v0 used dlt, and dlt is a stateful library. It stores state in local files and in some destination tables. This state gets corrupted, and starts behaving in very weird ways. This meant that depending on what that state had, what local files existed, and in what step of the ingestion journey the load is currently at, the load would behave very differently. When playing with a single source implementation this might be alright, but at the number of integration points and number of executions we operate at, this became a real problem.
I genuinely believe that this is a stateless problem. I don't have proof for this, but at this point I have a pretty good sense of what this problem is, and I genuinely believe this problem can be solved without an external state anywhere. At least for the usecases we wanted to solve. There are some edge cases that would benefit from having a state, however the simplicity and scalability we get from a stateless design dwarfs those edge cases by a wide margin.
Rewriting ingestr in Go: faster, better, more reliable
After these problems, and some signs around doing business with bad partners, we decided that we got where we wanted to be with ingestr v0 and it was a time for a rewrite. It proved that the concept was solid and many ingestion jobs could have been represented as simple source-destination URI pairs. It also proved that we had a solid business, and we could invest more into this.****
This also coincided with the lovely progress of AI agents. I have been very vocal about how AI friendly this problem was, and I had my opportunity to prove it. I could also do it in the best language for agents.
I don't want to write yet another article about why Go beats Python, go read it already. I believe we have found one of the best fits for Go here: a highly paralellizable problem, a deep need for self-contained binaries and a strong cross-platform compilation capabilities, and static validation of the code ahead of time. Combine this with agents, we managed to rebuild a large codebase in a completely different language with full feature parity.
We think the tools we produce should be fast enough to not get in the way. You should not be waiting around tens of minutes just to move a few million rows around. That's why the performance was an important factor since day 0 of the rewrite, and Go shines there quite decently. The problems we are dealing with are heavily parallelizable, and Go excels at concurrency, which makes it a great fit.
On top of that, there are a couple of things that puts us at an advantage:
ingestr is opinionated, which means we can optimize certain codepaths to be as performant as they can theoretically be.
We are aggressively utilizing concurrency, especially across systems that can handle the load and do not impose strict rate limits. (Looking at you, Hubspot.)
We utilize Apache Arrow internally, which allows us to avoid a lot of heavy memory operations and instead utilize the same data as quickly as possible across our sources and destinations.
We eliminated the state altogether, which allows us to run loads also externally parallelized, e.g. load data for the past 30 days, running as 30 parallel runs, one per each day.
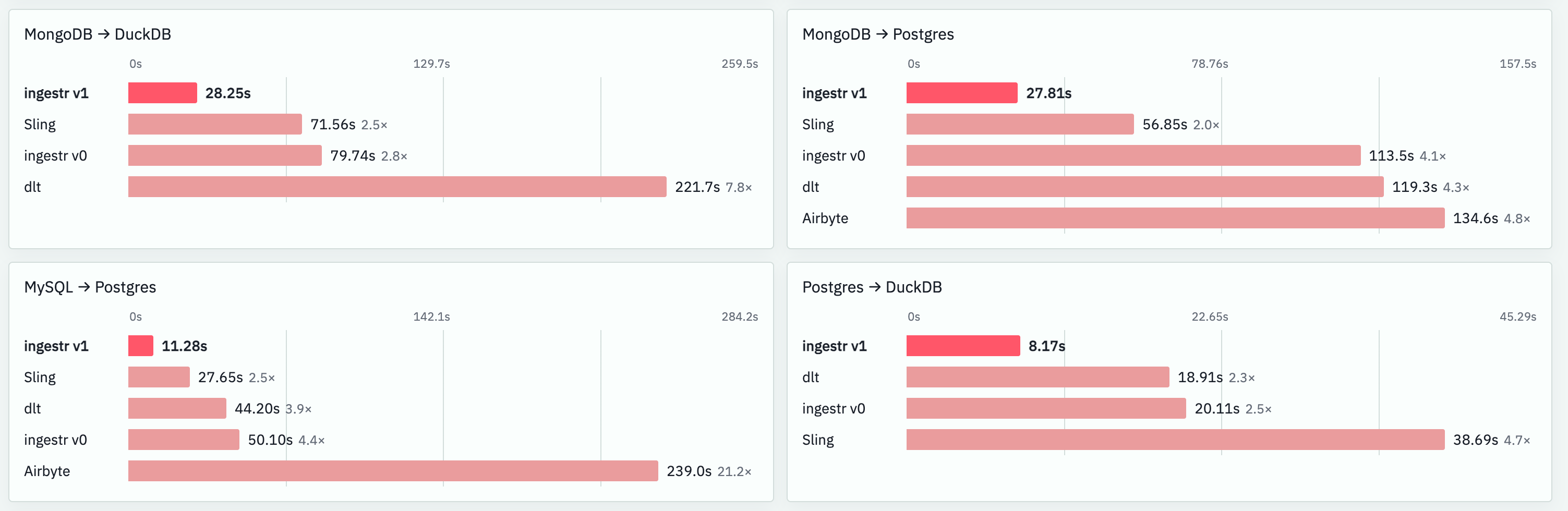
All these bits combined, ingestr v1 seems to be the fastest open-source data ingestion tool out there based on our benchmarks. We are more than happy to be corrected on our benchmark numbers, and all of the benchmarking logic is open-source.
You might be able to tell it by now, but we are an opinionated bunch. We want to evolve our tools to fit the needs of our customers, and we like doing things our way. The brand-new ingestr allows us to do exactly this. We are implementing new sources, new destinations, new options on ingestion logic, and more. This allows us to build the best data ingestion tooling in the market, while making it the easiest one too. Thanks to the simplicity of the new architecture, we have even built a little UI on top of it as a POC.
We have been rolling out ingestr v1 to Bruin Cloud customers and have executed thousands of runs already. We have ironed out a lot of the mismatches we have discovered over the past few months, and have been doing our primary feature development in the new version. The fact that it is in Go, a language that our team is very familiar with, and we have a large amount of tests covering a big chunk of the integration points, allows us to build out new features very quickly.
What's next?
This release sets the beginning of our tech independence. We have taken some intentional tech debt in the past, such as building upon other libraries, trying to walk around their limitations and whatnot to prove the value, and we have proven the value. We are building the foundations for a better way to work with data, and that requires us to have control over the tools we build upon.
ingestr is the fastest data ingestion tool in the market. At least among the open-source ones, by far. It is also one of the easiest ones to use, one of the most featureful one, and is built to be used both by humans and agents. This rewrite gives us the opportunity to continue improving it, and addressing problems much faster.