Education
What is CDC in data engineering? Change data capture explained
What is CDC in data engineering? Learn how change data capture records database changes, differs from ETL and incremental loading, and when to use it.
Read more
An honest 2026 guide to data ingestion tools, from Fivetran and Airbyte to dlt, Sling, Meltano, and ingestr. Which are open source, which connect to live company data, which support CDC and incremental loads, and which fit a modern AI data stack.

Kateryna Kozachenko
Marketing & Growth

TL;DR: The best data ingestion tools in 2026 are ingestr, Fivetran, Airbyte, dlt, Sling, Meltano, Stitch, Hevo Data, and Estuary Flow. They split into three groups: fully managed ELT services (Fivetran, Hevo, Stitch), open-source and code-first tools (Airbyte, dlt, Sling, Meltano, ingestr), and real-time CDC streaming (Estuary). The right pick depends on whether you want zero-maintenance and will pay for it, whether you want open source you can self-host, and whether ingestion is a standalone job or one step inside a larger AI data platform. ingestr is the fastest open-source pick we know of, and it doubles as the ingestion layer of a full platform.
Data ingestion is the least glamorous part of the stack and the part that breaks first. Before anyone asks a question, builds a dashboard, or trains a model, raw data has to land somewhere usable: your warehouse, your lake, your Postgres. Get ingestion wrong and everything downstream inherits the mess. The category has matured a lot, so this guide groups the tools by how they actually behave, with what each is good at, which connect to live company data, which support change data capture and incremental loads, and which expose an API or run in your own infrastructure.
We build Bruin and the open-source ingestr CLI, so we know that corner well, and we have spent a lot of time helping teams move off brittle pipelines. This is an honest rundown of the ingestion tools worth shortlisting in 2026. If you want orchestration rather than ingestion, see our best data pipeline tools guide; if you want to push data back into SaaS tools, see the reverse ETL guide. Corrections welcome at [email protected].
A data ingestion tool moves data from a source (a database, a SaaS app, a file, an API, an event stream) into a destination (a warehouse like Snowflake, BigQuery, or Databricks, or another database) on a schedule, and keeps it in sync. The good ones handle the parts that are tedious to write by hand:
Ingestion is distinct from transformation (modeling the raw tables into clean ones, the dbt or SQL job), from orchestration (scheduling and wiring the whole flow), and from reverse ETL (pushing modeled data back out to SaaS tools). Some tools do only ingestion. A platform does all of it in one place.
Most teams in 2026 do not pick a single tool by religion. They pick managed for the long tail of SaaS sources they do not want to babysit, and an open-source tool for the database-to-warehouse loads they want to control. And increasingly, they want ingestion to live inside the same platform as transformation, quality, and lineage so an AI agent can reason about the whole flow.
Nine tools, not ninety. We left out single-source wrappers and abandoned Singer taps. The criteria:
| Tool | Type | Open source | Interface | CDC / incremental | Best for |
|---|---|---|---|---|---|
| ingestr | Open-source CLI (+ platform) | Yes (MIT) | CLI + local web UI | Yes (6 strategies incl. SCD2) | Fast, code-light DB and SaaS loads you control |
| Fivetran | Managed ELT | No | SaaS UI | Yes | Hands-off SaaS sync, budget for scale |
| Airbyte | Open-source + Cloud | Yes | UI + API + CDK | Yes | Largest connector catalog, self-host or managed |
| dlt | Python library | Yes | Python code | Yes | Engineers who want ingestion as code in scripts |
| Sling | Open-source CLI | Yes | CLI + YAML | Yes | Fast database-to-database and file loads |
| Meltano | Open-source (Singer) | Yes | CLI + YAML | Yes (tap-dependent) | DataOps teams standardizing on Singer taps |
| Stitch | Managed ELT (Singer) | Partly | SaaS UI | Yes | Simple, low-volume managed syncs |
| Hevo Data | Managed ELT | No | SaaS UI | Yes (near real-time) | No-code teams wanting low-latency syncs |
| Estuary Flow | Real-time CDC | Partly | UI + CLI | Yes (streaming) | Low-latency change capture and streaming |
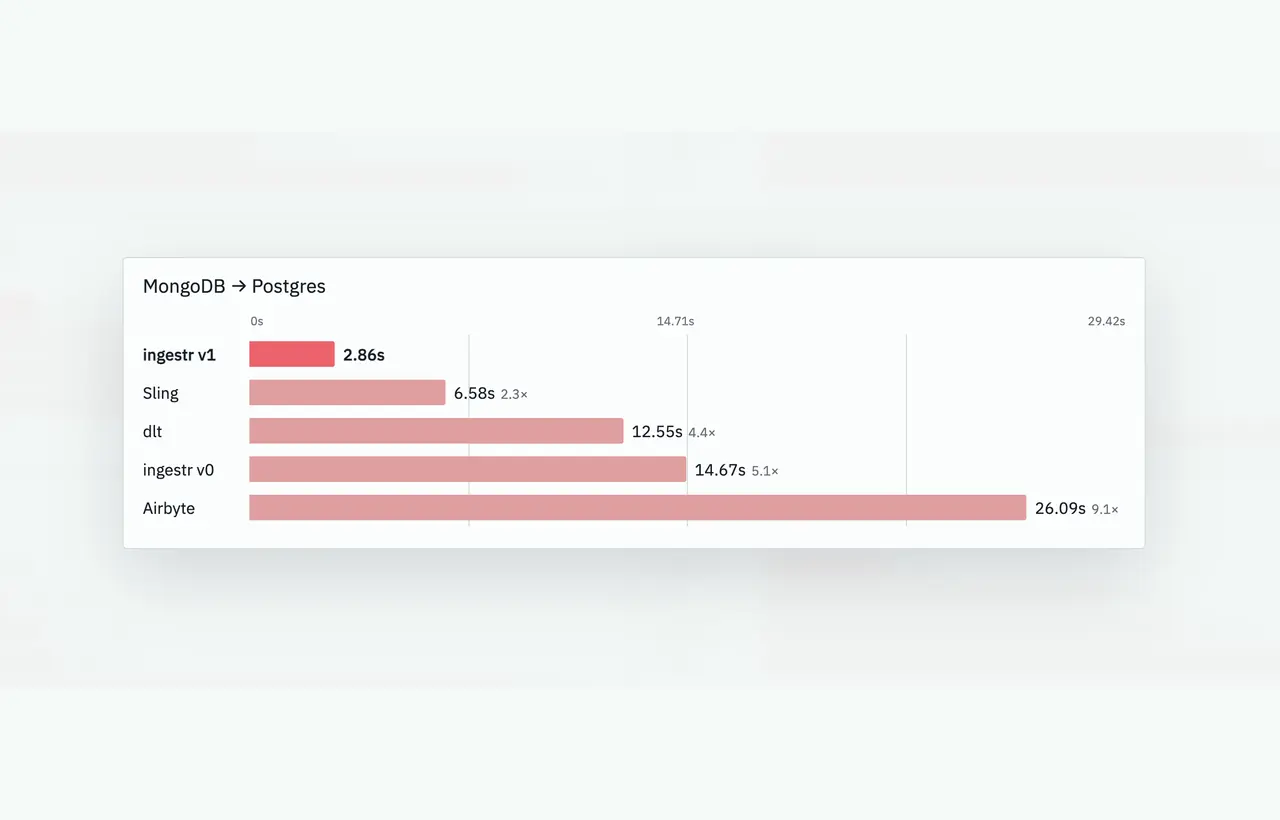
What it is: an open-source ingestion CLI. You give it a source URI and a destination URI and it moves the data: ingestr ingest --source-uri ... --dest-uri .... No connector code, no boilerplate. ingestr v1 is a ground-up rewrite that, in our benchmarks, loads 1M-row tables up to 12 times faster than the previous version, dlt, and Sling.
Why teams pick it: it is the rare tool that is both fast and code-light. Twenty-two databases and warehouses (each as source and destination) plus 40+ SaaS sources work out of the box, and six incremental strategies cover the real cases: replace, append, merge, delete+insert, the new truncate+insert, and SCD Type 2 with full row history. It runs as a single binary anywhere a binary runs (CI, Airflow, Dagster, Prefect, Kubernetes, cron), and there is a local web UI (ingestr server) for saving connections and watching runs. For anything not built in, the Bruin platform pipes through MCP to reach thousands more services.
Watch-outs: ingestr is an ingestion tool, not an orchestrator or a transformation engine. If you want ingestion, SQL and Python transformations, quality checks, column-level lineage, and an AI analyst in one place, that is the Bruin platform wrapped around it, where ingestr is the open-source ingestion layer.
What it is: the best-known fully managed ELT service, with one of the largest catalogs of maintained connectors and automatic schema handling.
Why teams pick it: you connect a source and never think about the sync again. The connector coverage and reliability for the long tail of SaaS tools is the benchmark everyone else is measured against.
Watch-outs: consumption-based pricing (billed on monthly active rows) is predictable when volumes are small and can climb sharply as they grow. You also do not control where the sync runs, which matters for some compliance setups.
What it is: the open-source connector platform, with a very large catalog (including community connectors) and a connector development kit for building your own. Available self-hosted or as Airbyte Cloud.
Why teams pick it: the breadth of connectors and the option to self-host make it the default open-source answer when Fivetran's bill gets uncomfortable or a source is not covered. The CDK means a missing connector is a project, not a dead end.
Watch-outs: self-hosting Airbyte is real infrastructure to run and upgrade, and community-connector quality varies. Teams often start self-hosted and move to Cloud once the maintenance adds up.
What it is: an open-source Python library for ingestion. You pip install dlt and write pipelines as Python, with automatic schema inference and evolution.
Why teams pick it: ingestion as code that lives inside your own scripts and repos, version-controlled like everything else. Great for engineers who want full programmatic control and are happy writing Python.
Watch-outs: it is a library, so you write and maintain more than you would with a CLI or a managed service. The flexibility is the cost.
What it is: a fast open-source CLI for moving data between databases and files, configured with simple flags or YAML.
Why teams pick it: it is quick and pleasant for database-to-database and file-to-warehouse loads, with a small footprint and a gentle learning curve.
Watch-outs: its strength is databases and files; the SaaS-source story is thinner than Fivetran, Airbyte, or ingestr. In our 1M-row benchmarks it was also slower than ingestr v1 across every source-destination pair we tested.
What it is: an open-source, CLI-first platform built on the Singer ecosystem of taps (sources) and targets (destinations), with a DataOps workflow.
Why teams pick it: if you have standardized on Singer or want an open, config-driven approach with everything in version control, Meltano gives you a structured home for it.
Watch-outs: you live and die by the quality of the available Singer taps, which varies a lot by source. Some taps are excellent, others are stale.
What it is: a simple managed ELT service (also Singer-based), long established and now part of the Talend / Qlik family.
Why teams pick it: it is straightforward and cheap for low-volume, standard syncs where you do not need much beyond "land this table in my warehouse."
Watch-outs: the connector catalog and feature pace lag the newer players, and transformation support is minimal. It is a fit for simple needs, less so for an evolving stack.
What it is: a no-code managed ELT platform aimed at near real-time syncs and business-friendly setup.
Why teams pick it: non-engineers can stand up pipelines quickly, and the low-latency syncing is a selling point for teams that need fresher data than a typical batch cadence.
Watch-outs: like other managed services, you trade control and cost predictability for convenience, and you are reliant on the vendor's connector coverage.
What it is: a real-time data movement platform built around change data capture and streaming, rather than scheduled batch syncs.
Why teams pick it: when you genuinely need low-latency CDC (seconds, not hours) into a warehouse or another system, Estuary is built for that from the ground up, with exactly-once semantics.
Watch-outs: real-time is more moving parts than batch. If your downstream consumers refresh hourly or daily anyway, the added complexity may not pay off.
There is no single best tool; it depends on your constraints. For fully managed convenience, Fivetran has the broadest connector catalog. For open source you control, ingestr is the fastest code-light option in our benchmarks, Airbyte has the largest catalog, and dlt is best if you want ingestion written as Python. If you want ingestion to be part of an end-to-end AI data platform, Bruin includes ingestr as its ingestion layer alongside transformations, quality checks, and an AI analyst.
ingestr (MIT licensed), Airbyte, dlt, Sling, and Meltano are open source and can be self-hosted. Fivetran and Hevo are fully managed and closed source. Stitch and Estuary have open-source roots or components but are used primarily as managed services.
Most serious tools support incremental loading. Fivetran, Airbyte, Hevo, and Estuary offer CDC from supported databases. ingestr ships six incremental strategies out of the box: replace, append, merge, delete+insert, truncate+insert, and SCD Type 2 with full row history. Estuary Flow is built specifically for real-time streaming CDC.
Data ingestion is the step that moves raw data from a source into your warehouse and keeps it in sync. A data pipeline is the broader flow that also transforms, validates, and orchestrates that data. Ingestion tools like Fivetran, Airbyte, and ingestr handle the first step; orchestration tools like Airflow, Dagster, and Bruin handle the whole flow. See our best data pipeline tools guide for the orchestration side.
Yes. Airbyte is the closest open-source equivalent for connector breadth, and ingestr is a faster, code-light CLI for the database and SaaS loads you want to run yourself without a per-row bill. Both can be self-hosted, so there is no consumption-based pricing as volumes grow. See Fivetran vs Bruin for a direct comparison.
Yes. All the major tools, including Fivetran, Airbyte, and ingestr, support Snowflake, BigQuery, and Databricks as destinations. ingestr supports those plus Redshift, Postgres, MySQL, MS SQL, ClickHouse, DuckDB, MotherDuck, and more, with each database available as both a source and a destination.
All three are open-source, code-first ingestion tools. dlt is a Python library you embed in your own code; Sling and ingestr are CLIs you run directly. In our internal benchmarks loading 1M-row tables across five common source-destination pairs, ingestr v1 was up to 12 times faster than dlt and Sling. ingestr also ships SCD Type 2 and a local web UI out of the box.
If you want to see how code-light ingestion feels, ingestr is open source and installs in one command. Grab it on GitHub, read the docs, or see how it fits into the full Bruin platform alongside transformations, quality checks, lineage, and an AI data analyst.
What is CDC in data engineering? Learn how change data capture records database changes, differs from ETL and incremental loading, and when to use it.
A practical comparison of dlt alternatives for data ingestion: Bruin CLI, ingestr, Airbyte, Sling, Meltano, and Fivetran, including a MongoDB to Postgres benchmark.

What is CDC streaming? Learn how it reads database logs, where Kafka fits, how it differs from batch CDC, and when its operational cost is worth it.
Practical updates on open-source data pipelines, AI analysts, governance, and what we are shipping at Bruin.