Pentaho vs Bruin: A Modern Alternative for Data Pipelines
A practical comparison of Pentaho and Bruin for teams evaluating PDI, Kettle, and legacy ETL alternatives. Bruin offers onboarding and migration planning for governed pipelines, DAC dashboards, MCP, and AI analytics.
Arsalan Noorafkan
Developer Advocate
Quick answer: This page is not making a claim about Pentaho's business status. It is a general alternatives page for teams asking whether their Pentaho Data Integration, Kettle, or older ETL setup still fits how data teams now build, review, govern, and serve data. If you want open-source-first pipelines as code, quality checks, lineage, Git review, hybrid deployment, DAC dashboards, MCP access, and an AI data analyst on top, Bruin is a cleaner replacement path. The Bruin team can also help with onboarding and migration planning.
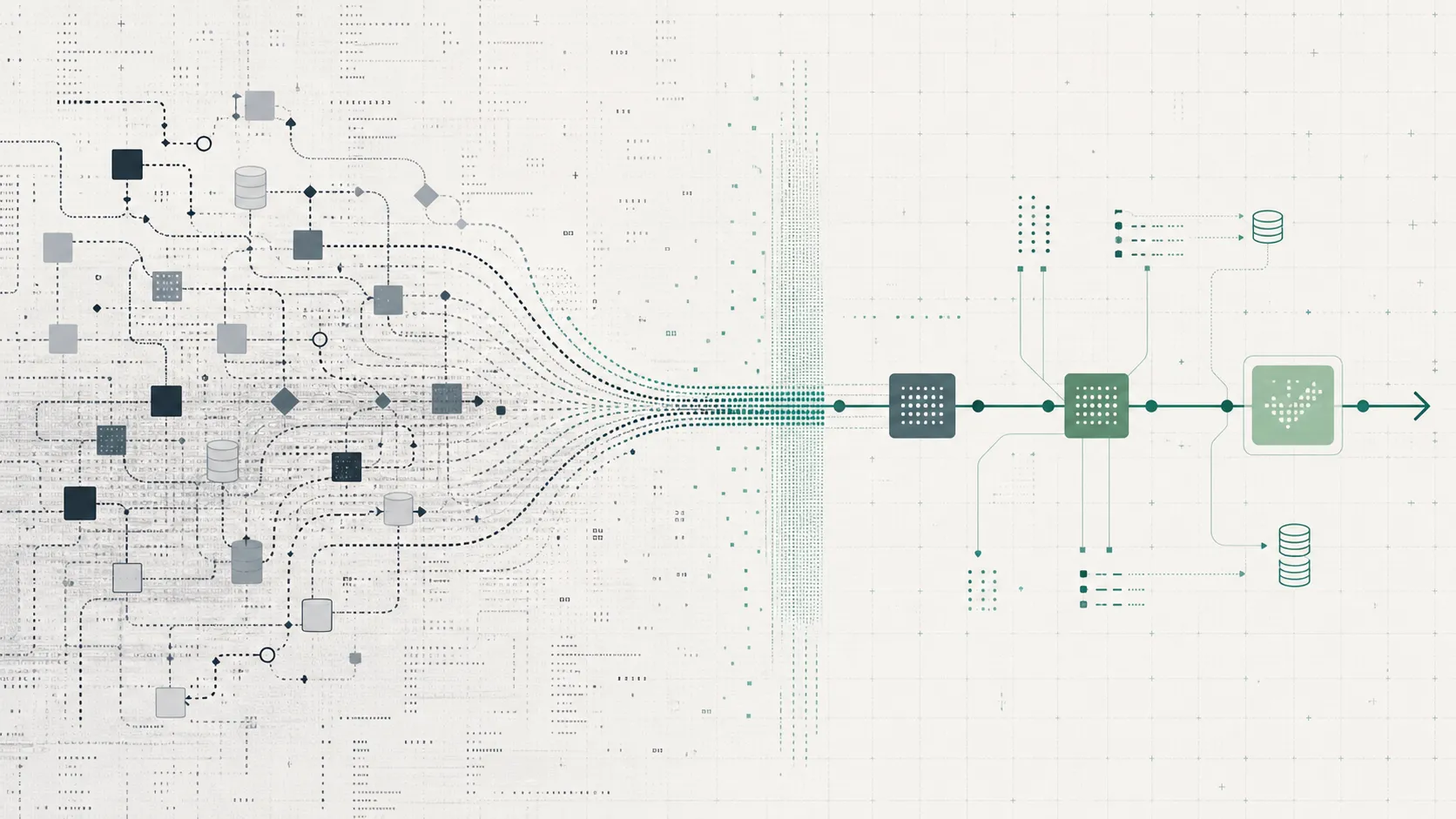
This matters because most Pentaho estates are not one product. They are a pile of PDI transformations, scheduled jobs, local Spoon workflows, custom scripts, server configuration, old reports, and tribal knowledge. The migration is not "replace a tool". It is "make the pipeline understandable again".
Pentaho has been around for a long time, and there is a reason people used it. PDI made ETL approachable. You could drag steps onto a canvas, connect them, run the job, and hand it to someone who did not want to write much SQL or Python.
For many teams, that was a proper unlock:
Visual ingestion and transformation flows
A large history of database, file, and enterprise data patterns
Familiar desktop development with Spoon
Server-side execution for enterprise deployments
A BI layer around the pipeline estate
If your workflows are stable and the team maintaining them is happy, you do not need a migration because a blog post says so.
But if you are here, it is probably because the old setup is starting to cost you.
The first problem is reviewability. Large visual transformations are easy to start and painful to govern. You can version files, sure, but reviewing a visual ETL diff is not the same thing as reviewing a SQL model, Python asset, or YAML config in Git.
The second problem is support and runtime drift. Pentaho's own lifecycle page says older versions outside the listed lifecycle are unsupported, and it specifically notes that Pentaho 9.3 is unsupported from July 1, 2026. If you are sitting on a long-lived PDI estate, that date is not trivia. It is a planning problem.
The third problem is AI readiness. An AI analyst only works if the data underneath is trustworthy. It needs asset ownership, freshness checks, lineage, metric definitions, access control, and auditability. A pile of ETL jobs can produce tables, but it usually does not produce enough context for governed AI analytics.
Bruin is an open-source-first data platform. Locally, teams use Bruin CLI and ingestr to build and run pipelines. In production, Bruin Cloud adds orchestration, scheduling, observability, catalog, lineage, SSO, RBAC, audit logs, cost visibility, and the AI data analyst.
The important part: ingestion, transformation, checks, and metadata live together.
Here is the kind of asset definition you end up with.
That is a lot less mystical than a big visual job. The source is clear, the dependency is clear, the owner is clear, and the checks are visible instead of buried in a side process.
Do not rewrite everything first. That is how migrations become expensive theatre.
Start with one flow:
Pick a critical Pentaho job that everyone understands.
Map its sources, transformations, outputs, schedule, owners, and downstream reports.
Recreate ingestion with ingestr or a Python materialization.
Move transformation logic into SQL or Python assets.
Add checks for row count, freshness, nulls, uniqueness, and important business rules.
Run Pentaho and Bruin in parallel until outputs match.
Retire the old job only after downstream consumers trust the new one.
The small detail that matters: add the checks before you declare victory. A pipeline that merely runs is not migrated. A pipeline that proves its output is healthy is migrated.
Pentaho migration
Want to map your Pentaho migration?
Send us the shape of your current PDI or Kettle setup. The Bruin team can help map what becomes ingestion, SQL/Python, checks, Bruin Cloud orchestration, MCP access, and DAC dashboards.
You want SQL and Python instead of visual job logic.
You need ingestion, transformation, checks, lineage, and orchestration in one framework.
You need hybrid deployment, private connectivity, or no direct production database access.
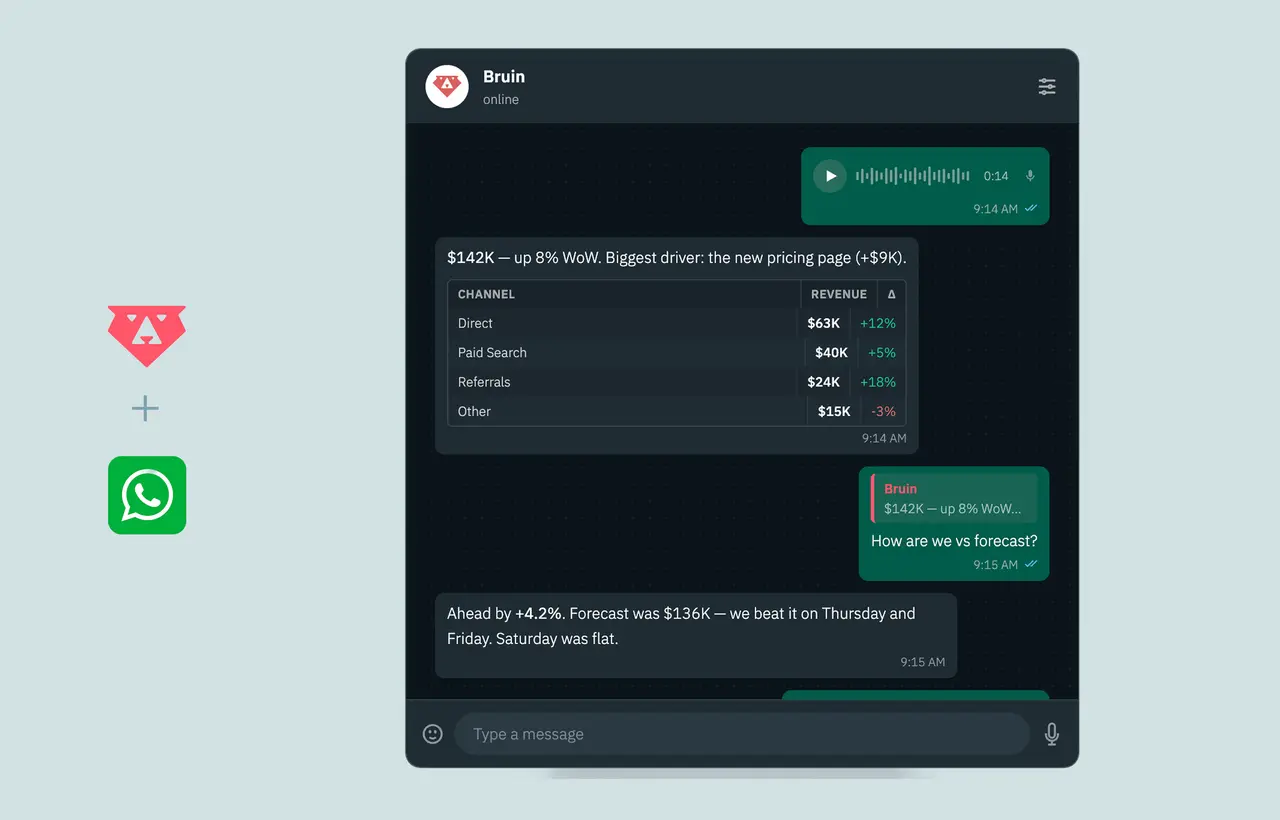
You want an AI data analyst in Slack, Teams, or browser that uses governed data context.
You want DAC dashboards and MCP access on top of the same governed platform.
You want open-source tools locally and managed governance when the team scales.
That last point is the big one. A modern data platform is not just the thing that moves rows. It is the context layer around the rows: ownership, lineage, freshness, definitions, access, quality, and audit.
If Pentaho is still working and nobody is asking for better governance, AI analytics, or code review, keep it.
But if your team is already discussing support windows, CE risk, Java/runtime maintenance, visual-job sprawl, or how to make old ETL feed a modern AI analyst, Bruin is worth testing. Start with one pipeline. Make it boring. Prove parity. Then expand.