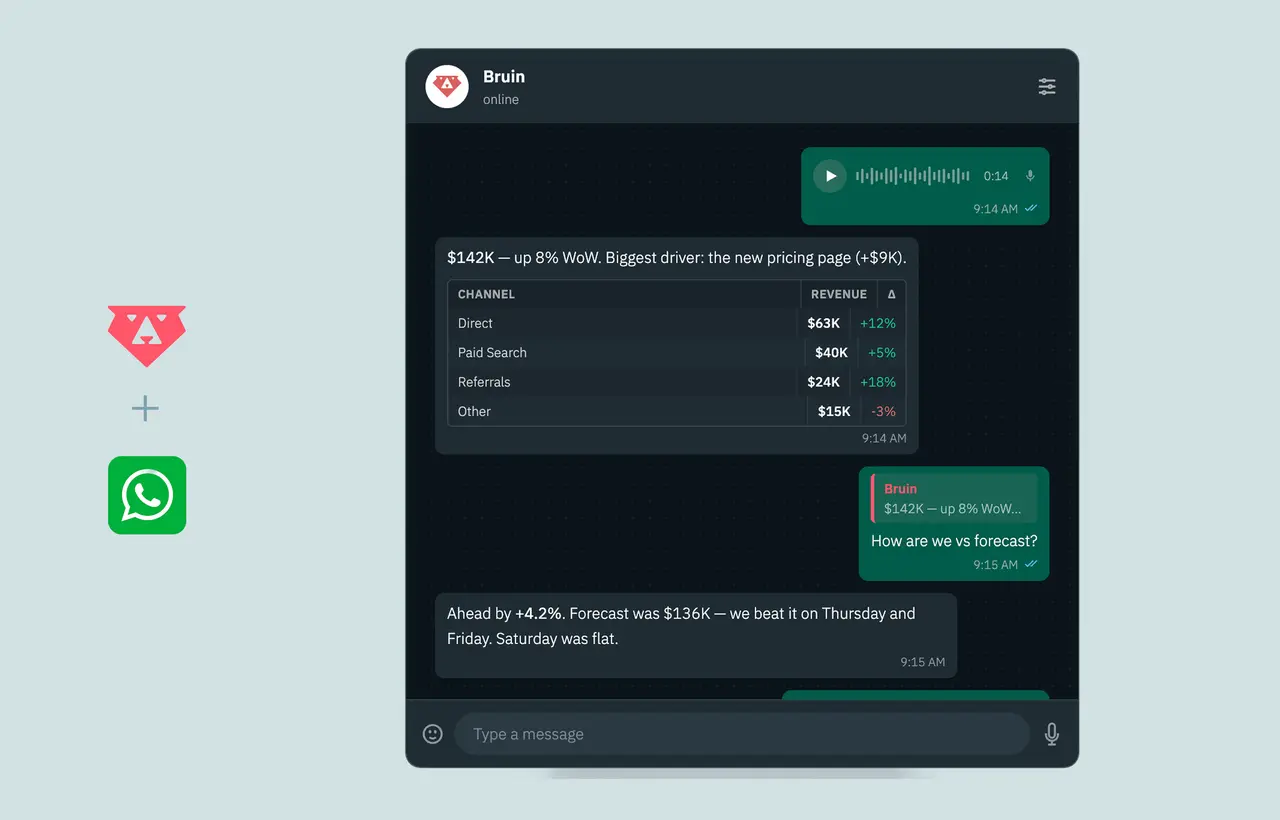
The first Bruin Project Competition started as a companion challenge for DataTalksClub learners working through the Data Engineering Zoomcamp.
The goal was practical: build an end-to-end data pipeline with Bruin, publish the project, and explain how the pieces work together. The competition was originally aimed at Zoomcamp participants, but interest quickly came from people outside the course as well. Because of that, we opened the competition to anyone who wanted to build a complete data project with Bruin.
The first round produced over 70 showcased projects. Each accepted project has a public showcase page, a GitHub repository link, and a certificate attached to the project page.
For anyone thinking about doing the Zoomcamp course or joining a future Bruin competition, this post is a recap of how the first round worked, what people built, what tooling patterns showed up, and what made the strongest submissions stand out.
The Bruin Project Competition is a community data engineering competition where participants build end-to-end data pipelines with Bruin. The first round started through DataTalksClub Data Engineering Zoomcamp, then opened to the wider community because people outside the course wanted to participate. Builders used Bruin for ingestion, transformation, orchestration, data quality checks, lineage, metadata, AI analysis, and project documentation. The first round produced over 70 public projects in the Bruin Project Showcase and included prizes such as a Mac Mini, annual Claude Pro subscriptions, and participation Claude Pro subscriptions.
The competition was not about submitting a screenshot or a single notebook. Participants were expected to build a complete data project that another person could inspect, run, and learn from.
The core requirements were:
- build an end-to-end data pipeline
- use Bruin for the main pipeline workflow
- include ingestion, transformation, orchestration, and checks
- publish a GitHub repository with a useful README
- share the project with the community
- submit the project for review and showcase publication
Most projects followed a familiar pattern: source data came from an API, public dataset, file, or operational source; Bruin assets handled ingestion and transformation; data quality checks validated the outputs; a warehouse or local analytical database stored the modelled data; and a dashboard, report, or AI analysis layer presented the result.
The Bruin CLI was the main tool people used for SQL and Python assets, asset dependencies, pipeline runs, validation, data quality checks, lineage, and metadata. Some participants also used ingestr for ingestion. Others combined Bruin with tools they already knew, including dbt, Kestra, Dagster, Terraform, Streamlit, Looker Studio, Evidence.dev, BigQuery, DuckDB, GitHub Actions, and cloud storage.
That flexibility ended up being important. The strongest projects did not treat Bruin as a replacement for every tool in the stack. They used it as the place where the workflow became understandable.
The Data Engineering Zoomcamp is already built around hands-on learning. People do not just read about Docker, warehouses, orchestration, analytics engineering, and batch processing; they build projects and submit work.
Bruin fit naturally into that stage of the course because it gives learners a way to keep the whole project in one place:
- Python assets for ingestion and procedural work
- SQL assets for transformations and marts
- asset dependencies instead of a separate DAG definition layer
- data quality checks close to the assets they validate
- local development with DuckDB or cloud development with BigQuery and other warehouses
- metadata, lineage, and validation commands that make the project easier to inspect
At the beginning, some people asked a fair question: if the Zoomcamp already covers tools like dbt and orchestration systems, is a Bruin module redundant?
That question is useful because it gets to the real problem with modern data tooling. The individual tools are strong, but they are often isolated. One tool ingests. Another transforms. Another orchestrates. Another checks quality. Another serves documentation. Another gives agents or analysts a partial view of the project. For a learner, and often for a working data team, the hard part becomes stitching the system together and keeping the context coherent.
The first round of the competition made this very visible. Participants started with that "how is this different from dbt, Kestra, or dltHub?" question, but many projects ended up showing the answer in practice: Bruin was useful because it gave the pipeline one project structure, one dependency graph, one place for SQL and Python, and one set of assets that humans and AI agents could inspect.
The range of projects was much wider than a typical course project list.
The top community-voted projects, the group behind the annual Claude Pro prize expansion, showed how wide the competition became. Global Energy Transition Pipeline by Joseph Obi analysed 125 years of global energy data across 200+ countries. It used Bruin with DuckDB, Evidence.dev, GitHub Actions, seed assets, SQL marts, 54 automated checks, bruin ai enhance, daily scheduling, lineage, and validation in CI.
KAIROSKOP - A Collective Attention Observatory by Carlos Saritama took a more conceptual direction, tracking shifts in collective attention rather than building a standard business dashboard. That kind of project is useful because it shows Bruin being used outside the usual ecommerce or finance tutorial shape.
Skypulse Streaming Pipeline by Alexander Daniel Rios combined flight positions, weather, and seismic events into a real-time airspace risk view. It used Redpanda and Apache Flink for streaming windows, Supabase as a landing layer, Bruin for layered modelling from staging to marts, and Streamlit for visualization.
Lassa-Watch by Joseph Akintola tracked Lassa fever outbreak data across eight Nigerian states from 2021 to 2025. The project combined NCDC epidemiological data, Open-Meteo climate data, and healthcare infrastructure metrics, then used Python assets, DuckDB SQL assets, a full DAG, built-in checks, custom checks, materialization, and Bruin MCP connected to Claude Code for AI-powered pipeline analysis.
Haxball Analytics by Deniz Arda Aslan turned a live Haxball room into a sports analytics system. It collected match events and player/ball coordinates, then used Bruin for JSONL ingestion, validation, SQL transformations, orchestration, and DuckDB marts powering xG, player rankings, lineups, match summaries, and pipeline health.
Other strong projects covered food security pressure, IoT plant monitoring with Raspberry Pi and ESP32, Istanbul public transportation insights, bank customer churn, urbanization and mobility intelligence, and Nigeria-focused economic pipeline work.
The important part is not only the topics. It is the structure. Many projects had layered models, quality checks, CI validation, clear READMEs, and dashboards or AI analysis built on top of modelled data. That is much closer to how real data work happens than a standalone analysis notebook.
Across the over 70 projects, a few Bruin patterns showed up repeatedly.
Python assets were used for ingestion, API extraction, file parsing, machine learning inference, custom business logic, and cases where SQL alone would have been awkward.
SQL assets were used for staging, intermediate models, marts, reporting tables, and analytical outputs. Several projects used DuckDB locally while others used BigQuery or other cloud warehouses.
Asset dependencies were used to define the project graph without maintaining a separate orchestration layer just for task order. This was especially useful for projects with mixed Python and SQL workflows.
Data quality checks were one of the clearest themes. Participants used built-in checks like not_null, unique, positive, and accepted values, plus custom SQL checks for project-specific rules. The better submissions treated checks as part of the asset definition, not as an afterthought.
Lineage and validation helped make projects easier to inspect. Several projects used bruin validate, lineage output, and GitHub Actions to make sure the pipeline stayed runnable after changes.
AI workflows also appeared in a few different ways. Some participants used bruin ai enhance for documentation, column descriptions, tags, and suggested checks. Others connected Bruin MCP to coding agents such as Claude Code so the agent could inspect the project structure, understand assets, and help analyze the pipeline without guessing from a disconnected prompt.
One theme came up several times during the first round: Bruin can feel confusing at first if you already know dbt, Kestra, dltHub, or other modern data tools.
That reaction makes sense. If you look at Bruin as "another dbt" or "another orchestrator" or "another ingestion wrapper", it can sound redundant. But the competition projects showed a different pattern.
Bruin was useful when the project needed a unifying layer:
- ingestion and transformation in the same repository
- SQL and Python assets in the same DAG
- checks attached to the assets they validate
- local runs and cloud-ready structure
- metadata and lineage close to the code
- a project shape that an AI agent can read, run, and maintain
That last point matters more now than it did a few years ago. Data teams are not only building for humans anymore. They are also building for agents that need to inspect pipelines, understand schemas, run checks, generate documentation, investigate failures, and propose changes.
When the pipeline context is split across five tools, agents have the same problem humans do: they need to reconstruct the system before they can help. A unified project structure makes that easier. The files describe the assets. The assets describe their dependencies. The checks describe assumptions. The metadata explains meaning. The run history and validation commands tell the agent what is healthy and what is broken.
This does not mean every team should throw away their existing stack. In fact, some competition projects used Bruin alongside dbt, Dagster, Terraform, BigQuery, Streamlit, and other tools. The useful lesson is that modern data platforms are all moving toward the same direction anyway: fewer disconnected layers, more shared context, and better interfaces for both people and AI agents.
The first round included three prize categories:
- Mac Mini for the Outstanding Project
- annual Claude Pro subscriptions for top community-voted projects
- one-month Claude Pro subscriptions for eligible participation submissions
The annual Claude Pro prize was originally planned for the top 3 community-voted projects. After seeing the quality and volume of submissions, we expanded it to the top 5.
Each accepted project also received a certificate through its showcase page. This matters for future participants because the competition is not only about winning a prize. A public project page, GitHub repository, and certificate can become part of a portfolio, especially for people using the Zoomcamp to move into data engineering or strengthen their practical project experience.
If you are planning to do the Zoomcamp or join a future Bruin Project Competition, the best advice is to choose a project where the pipeline itself matters.
Pick a domain where there is a real data problem:
- multiple sources to combine
- messy ingestion
- transformations that require modelling decisions
- checks that would catch meaningful errors
- a final question someone might actually care about
- a README that explains how another person can run and inspect the work
The strongest submissions were not necessarily the biggest. They were the ones where the project structure made sense, the checks protected important assumptions, and the final analysis clearly came from the modelled data.
Start by browsing the Project Showcase. Open a few repositories. Look at how people organized assets, wrote checks, separated staging from marts, used DuckDB or BigQuery, and documented their decisions. That will teach you more than copying any single stack.
For course context, start with DataTalksClub, the Data Engineering Zoomcamp page, and the Zoomcamp GitHub repository. For Bruin-specific implementation, use the Bruin CLI docs and the showcase projects as references.
The Bruin Project Competition is a community data engineering challenge where participants build end-to-end pipelines with Bruin. Projects usually include ingestion, transformation, orchestration, data quality checks, documentation, and an analytical output.
The first round started as part of the DataTalksClub Data Engineering Zoomcamp. Because people outside the course also wanted to participate, Bruin opened the competition to the wider data community.
As of June 30, 2026, the Bruin Project Showcase includes over 70 accepted community projects from the first round.
You can browse them in the Bruin Project Showcase. Each project page includes the project description, author, GitHub repository, supporting links when available, and a certificate.
High community-voted and notable projects included Global Energy Transition Pipeline, KAIROSKOP, Skypulse Streaming Pipeline, Lassa-Watch, Haxball Analytics, Global Food Security Pressure, IoT Smart Plant Monitoring, and Istanbul Transportation Insights Pipeline.
Participants used Python assets, SQL assets, asset dependencies, DuckDB and BigQuery connections, materializations, data quality checks, custom checks, lineage, bruin validate, bruin ai enhance, GitHub Actions validation, and Bruin MCP for agent-assisted pipeline analysis.
dbt, Kestra, and dltHub each solve important parts of the data workflow. Bruin is useful when a project needs a unifying structure across ingestion, SQL and Python transformations, orchestration, quality checks, metadata, lineage, and AI-agent-readable project context.
Yes. Accepted projects in the showcase include a certificate on the individual project page, so participants can share public proof of what they built.
The first round included a Mac Mini for the Outstanding Project, annual Claude Pro subscriptions for top community-voted projects, and one-month Claude Pro subscriptions for eligible participation submissions.
The annual Claude Pro subscriptions were originally planned for the top 3 community-voted projects, but Bruin expanded them to the top 5 after seeing the quality and sophistication of the submissions.